Tekoäly on yksi nopeimmin kasvavista teknologioista, jotka käyttävät koneoppimisalgoritmeja mallien kouluttamiseen ja testaamiseen valtavan datan avulla. Tiedot voidaan tallentaa eri muodoissa, mutta suuria kielimalleja varten LangChainilla käytetään JSON-tyyppiä. Koulutus- ja testaustietojen on oltava selkeitä ja täydellisiä ilman epäselvyyksiä, jotta malli voi toimia tehokkaasti.
Tämä opas esittelee pydanttisen JSON-jäsentimen käytön LangChainissa.
Kuinka käyttää Pydantic (JSON) -jäsennintä LangChainissa?
JSON-tiedot sisältävät datan tekstimuodon, joka voidaan kerätä web-kaappauksen ja monien muiden lähteiden, kuten lokien jne., avulla. Tietojen tarkkuuden vahvistamiseksi LangChain käyttää Pythonin pydantista kirjastoa prosessin yksinkertaistamiseksi. Jos haluat käyttää pydantista JSON-jäsennintä LangChainissa, käy läpi tämä opas:
Vaihe 1: Asenna moduulit
Aloita prosessi asentamalla LangChain-moduuli käyttääksesi sen kirjastoja jäsentimen käyttämiseen LangChainissa:
pip Asentaa langchain
Käytä nyt ' pip asennus ”-komento hankkia OpenAI-kehys ja käyttää sen resursseja:
pip Asentaa openai
Kun olet asentanut moduulit, muodosta yhteys OpenAI-ympäristöön antamalla sen API-avain käyttämällä ' sinä ' ja ' getpass ”kirjastot:
tuo meilletuoda getpass
os.environ [ 'OPENAI_API_KEY' ] = getpass.getpass ( 'OpenAI API Key:' )

Vaihe 2: Tuo kirjastot
LangChain-moduulin avulla voit tuoda tarvittavat kirjastot, joita voidaan käyttää kehotteen mallin luomiseen. Kehotteen mallissa kuvataan tapa kysyä kysymyksiä luonnollisella kielellä, jotta malli voi ymmärtää kehotteen tehokkaasti. Tuo myös kirjastoja, kuten OpenAI ja ChatOpenAI luodaksesi ketjuja käyttämällä LLM:iä chatbotin rakentamiseen:
langchain.prompts -tuonnista (PromptTemplate,
ChatPromptTemplate,
HumanMessagePromptTemplate,
)
Tuo OpenAI osoitteesta langchain.llms
langchain.chat_modelsista tuo ChatOpenAI
Tuo sen jälkeen pydantiset kirjastot, kuten BaseModel, Field ja validaattori, jotta voit käyttää JSON-jäsennintä LangChainissa:
Tuo PydanticOutputParser osoitteesta langchain.output_parserspydantic importista BaseModel, Field, validator
kirjoittamalla tuontiluettelo
Vaihe 3: Mallin rakentaminen
Kun olet hankkinut kaikki kirjastot pydantisen JSON-jäsentimen käyttöä varten, hanki valmiiksi suunniteltu testattu malli OpenAI()-menetelmällä:
mallin_nimi = 'text-davinci-003'lämpötila = 0,0
malli = OpenAI ( mallinimi =mallin_nimi, lämpötila = lämpötila )
Vaihe 4: Määritä Actor BaseModel
Rakenna toinen malli saadaksesi vastauksia näyttelijöihin, kuten heidän nimiinsä ja elokuviinsa, pyytämällä näyttelijän filmografiaa:
luokan näyttelijä ( Perusmalli ) :nimi: str = Kenttä ( kuvaus = 'Päänäyttelijän nimi' )
film_names: Lista [ str ] = Kenttä ( kuvaus = 'Elokuvat, joissa näyttelijä oli pääosassa' )
näyttelijä_kysely = 'Haluan nähdä minkä tahansa näyttelijän filmografian'
parser = PydanticOutputParser ( pydantinen_objekti = Näyttelijä )
kehote = PromptTemplate (
sapluuna = 'Vastaa käyttäjän kehotteeseen. \n {format_instructions} \n {kysely} \n ' ,
input_variables = [ 'kysely' ] ,
osittaiset_muuttujat = { 'muoto_ohjeet' : parser.get_format_instructions ( ) } ,
)
Vaihe 5: Perusmallin testaus
Hanki tulos käyttämällä parse()-funktiota tulosmuuttujan kanssa, joka sisältää kehotteeseen luodut tulokset:
_input = kehote.format_prompt ( kysely =näyttelijä_kysely )lähtö = malli ( _input.to_string ( ) )
parser.parse ( ulostulo )
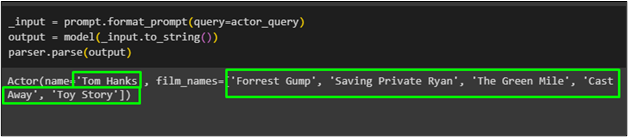
Näyttelijä nimeltä ' Tom Hanks ” luettelo hänen elokuvistaan on haettu mallista käyttämällä pydantic-toimintoa:
Siinä on kyse pydantisen JSON-jäsennyksen käyttämisestä LangChainissa.
Johtopäätös
Jos haluat käyttää pydantista JSON-jäsennintä LangChainissa, asenna LangChain- ja OpenAI-moduulit muodostaaksesi yhteyden niiden resursseihin ja kirjastoihin. Sen jälkeen tuo kirjastot, kuten OpenAI ja pydantic, luodaksesi perusmallin ja tarkistaaksesi tiedot JSON-muodossa. Perusmallin rakentamisen jälkeen suorita parse()-funktio, joka palauttaa kehotteen vastaukset. Tämä viesti osoitti pydantisen JSON-jäsentimen käyttöprosessin LangChainissa.