Joskus annettu tietojoukko ei ole yhdessä CSV-tiedostossa. Ne ovat kaikki eri Excel-taulukoissa. Tiedät jo, että on parempi suorittaa kaikki laskennalliset tai esikäsittelytoiminnot yhdelle tietojoukolle usean tietojoukon sijaan. Se vähentää tai säästää aikaa, jonka tarvitsemme esikäsittelytehtäviin. Tietoanalyytikkona tai datatieteilijänä saatat myös usein joutua ylikuormittumaan useista CSV-tiedostoista, jotka on yhdistettävä ennen kuin aloitat käytettävissä olevien tietojen analysoinnin tai tutkimisen. Toisaalta ei aina ole mahdollista, että kaikki tiedostot saadaan yhdestä tai samasta tietolähteestä ja niillä on samat sarakkeiden/muuttujien nimet ja tietorakenne. Tämä viesti opettaa sinua yhdistämään kaksi tai useampia CSV-tiedostoja, joilla on samanlainen tai erilainen sarakerakenne.
Miksi yhdistää CSV-tiedostoja?
Tietojoukko voi olla tiettyyn aiheeseen liittyvien arvojen tai numeroiden kokoelma tai ryhmä. Esimerkiksi jokaisen oppilaan testitulokset tietyllä luokalla ovat esimerkki tietojoukosta. Suurien tietojoukkojen koon vuoksi ne tallennetaan usein erillisiin CSV-tiedostoihin eri luokkia varten. Jos meidän on esimerkiksi tutkittava potilas tietyn taudin varalta, meidän on otettava huomioon kaikki tekijät, mukaan lukien hänen sukupuolensa, potilastiedot, ikä, sairauden vakavuus jne. Näin ollen CSV-tietojen yhdistäminen on tarpeen erilaisten ennustajaan vaikuttavien tekijöiden tutkimiseksi. näkökohtia. Laskenta- tai esikäsittelytehtäviä suoritettaessa on myös parempi työskennellä ja hallita yhtä tietojoukkoa useiden tietojoukkojen sijaan. Se säästää muistia ja muita laskentaresursseja
Kuinka yhdistää CSV-tiedostoja Pythonissa?
Pythonissa on useita tapoja ja menetelmiä yhdistää kaksi tai useampia CSV-tiedostoja. Alla olevassa osiossa käytämme append(), concat() ja merge()-funktioita jne. CSV-tiedostojen yhdistämiseen pandas-tietokehykseksi, jolloin datakehykset muunnetaan yhdeksi CSV-tiedostoksi. Opetamme kuinka yhdistää useita CSV-tiedostoja, joilla on samanlainen tai muuttuva sarakerakenne.
Tapa 1: CSV-tiedostojen yhdistäminen samankaltaisten rakenteiden tai sarakkeiden kanssa
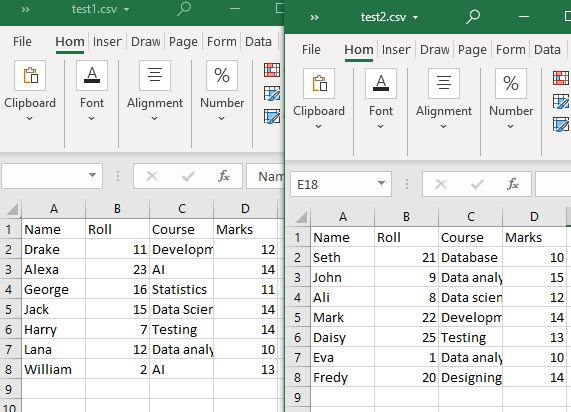
Nykyisessä työhakemistossamme on kaksi CSV-tiedostoa, 'test1' ja 'test2'.
Esimerkki # 1: Append()-funktion käyttö
Molemmat CSV-tiedostot ovat rakenteeltaan samanlaisia. Funktiota glob() käytetään tässä menetelmässä vain työhakemiston CSV-tiedostojen luetteloimiseen. Sitten käytämme 'pandas.DataFrame.append()' CSV-tiedostojemme lukemiseen (yhteisellä taulukkorakenteella).

Lähtö:
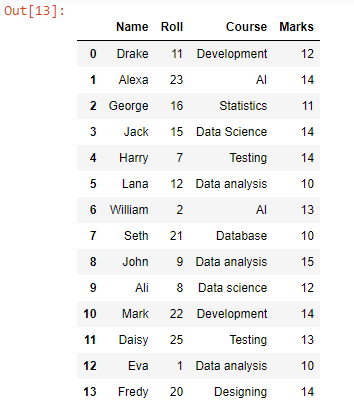
Append-toiminnolla olemme lisänneet tai lisänneet jokaisen datarivin test2.csv:stä test1.csv:n tietorivien alle, koska voidaan nähdä, että kaikki tiedoston tietorivit on yhdistetty. Muuntaaksesi tämän tietokehyksen CSV-muotoon, voimme käyttää to_csv()-funktiota.

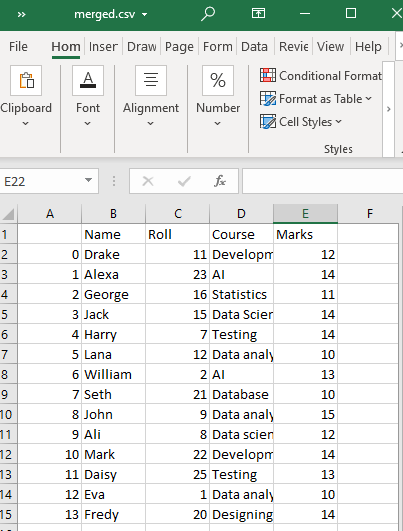
Tämä luo yhdistetyn CSV-tiedoston 'test1' ja 'test2' CSV-tiedostoista työhakemistoomme määritetyllä nimellä, eli merged.csv.
Esimerkki # 2: Concat()-funktion käyttö
Tuomme pandamoduulin ensin. Karttamenetelmä lukee jokaisen hyväksymämme CSV-tiedoston pd.read_csv()-komennolla. Nämä yhdistetyt tiedostot (CSV-tiedostot) yhdistetään sitten oletuksena riviakselia pitkin käyttämällä funktiota pd.concat(). Jos haluamme yhdistää CSV-tiedostoja vaakatasossa, voimme ohittaa akseli=1. Ohitusindeksin määrittäminen = True luo myös jatkuvia indeksiarvoja yhdistetylle tietokehykselle.

Pd.read_csv() välitetään concat()-funktion sisällä CSV-tiedostojen lukemiseksi pandas-tietokehykseen ketjutuksen jälkeen.
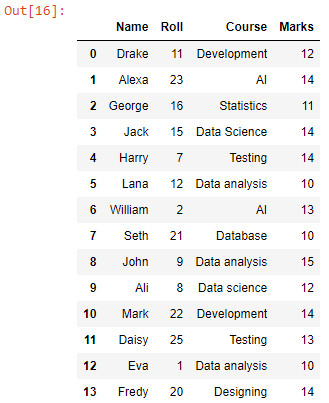
Olemme saaneet tietokehyksen, jossa on yhdistetty data kaikista työhakemiston CSV-tiedostoista. Muunnetaan se nyt CSV-tiedostoksi.
Yhdistetty CSV-tiedostomme luodaan nykyiseen hakemistoon.
Tapa 2: CSV-tiedostojen yhdistäminen eri rakenteiden tai sarakkeiden kanssa
Keskustelimme CSV-tiedostojen yhdistämisestä samoilla sarakkeilla ja rakenteella ensimmäisessä menetelmässä. Tässä menetelmässä yhdistämme CSV-tiedostoja erilaisilla sarakkeilla ja rakenteilla.
Esimerkki # 1: Merge()-funktion käyttö
Pandas-moduulin pandas.merge()-funktio voi yhdistää kaksi CSV-tiedostoa. Yhdistäminen tarkoittaa yksinkertaisesti kahden tietojoukon yhdistämistä yhdeksi tietojoukoksi jaettujen sarakkeiden tai attribuuttien perusteella.
Voimme yhdistää tietokehykset neljällä eri tavalla:
- Sisäinen
- Oikein
- Vasen
- Ulompi
Tällaisten yhdistämisten suorittamiseen käytämme kahta CSV-tiedostoa.
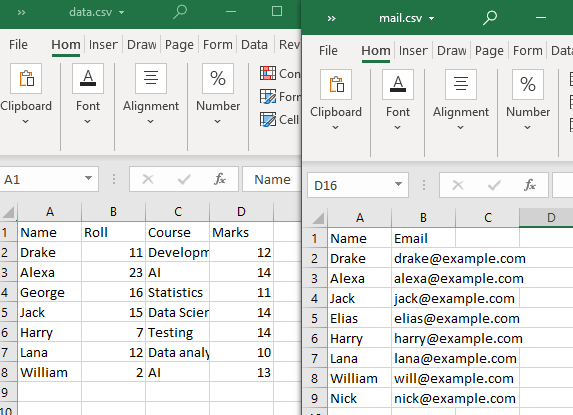
Huomaa, että molempien CSV-tiedostojen on jaettava vähintään yksi määrite tai sarake. Kuten havaittiin, molemmat CSV-tiedostot jakavat sarakkeen 'Nimi' ja jotkin sen attribuutit.
Yhdistä käyttämällä sisäistä liitosta
Parametrin how=’inner määrittäminen merge()-funktiossa yhdistää kaksi datakehystä määritetyn sarakkeen mukaisesti ja antaa sitten uuden datakehyksen, joka sisältää vain rivit, joilla on samat/samat arvot molemmissa alkuperäisissä tietokehyksissä.
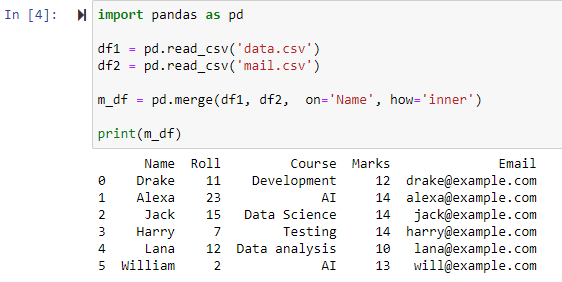
Kuten voidaan nähdä, toiminto on yhdistänyt molemmat CSV-tiedostot ja palauttanut rivit sarakkeen 'Nimi' yleisten attribuuttien perusteella.
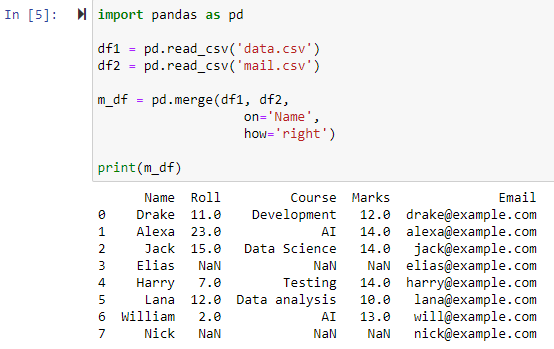
Yhdistä käyttämällä oikeaa ulkoliitosta
Kun parametri how=’right’ on määritetty, molemmat datakehykset yhdistetään parametrille ‘on’ määrittämämme sarakkeen perusteella. Ja uusi tietokehys, joka sisältää kaikki rivit oikeanpuoleisesta datakehyksestä, mukaan lukien rivit, joille vasen datakehys ei sisällä arvoja, palautetaan, ja vasemman datakehyksen sarakkeen arvoksi on asetettu NAN.
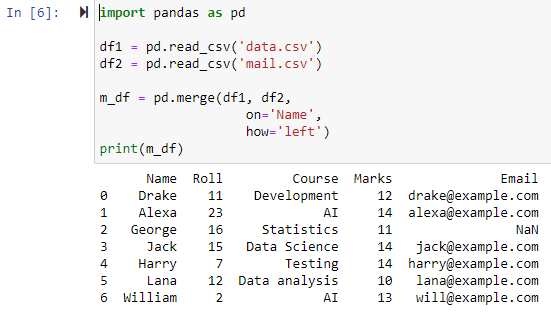
Yhdistä käyttämällä vasenta ulkoliitosta
Kun parametri on määritetty arvoksi 'vasen', nämä kaksi datakehystä yhdistetään määritetyn sarakkeen perusteella käyttämällä 'on'-parametria, jolloin palautetaan uusi tietokehys, jossa on kaikki rivit vasemmasta datakehyksestä sekä kaikki rivit, joissa on NAN. tai nolla-arvot oikeassa datakehyksessä ja asettaa oikean datakehyksen sarakkeen arvoksi NAN.
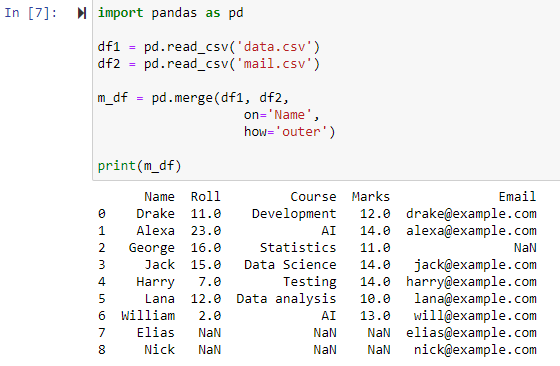
Yhdistä käyttämällä täydellistä ulkoliitosta
Kun how='outer' on määritetty, nämä kaksi datakehystä yhdistetään 'on'-parametrille määritetyn sarakkeen mukaan, palauttaen uuden datakehyksen, joka sisältää sekä df1- että df2-tietokehysten rivit, ja asettaa NAN arvoksi mille tahansa riville. joiden tiedot puuttuvat jostakin tietokehyksestä.
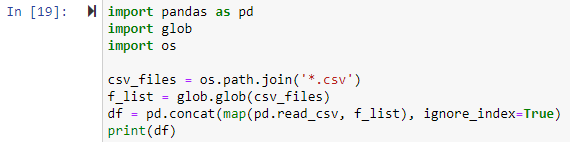
Esimerkki # 2: Kaikkien CSV-tiedostojen yhdistäminen työhakemistossa
Tässä menetelmässä yhdistämme kaikki .csv-tiedostot pandas DataFrame -kehykseen glob-moduulin avulla. Kaikki kirjastot oli tuotava ensin. Seuraavaksi asetamme polun jokaiselle yhdistettävälle CSV-tiedostolle. Tiedostopolku on os.path.join()-funktion ensimmäinen argumentti alla olevassa esimerkissä, ja toinen argumentti on joko yhdistettävät polun komponentit tai .csv-tiedostot. Tässä lauseke '*.csv' etsii ja palauttaa jokaisen tiedoston työhakemistosta, joka päättyy .csv-tiedostotunnisteeseen. Funktio glob.glob(fies joined) hyväksyy syötteeksi luettelon yhdistettyjen tiedostojen nimistä ja tulostaa luettelon kaikista yhdistetyistä/yhdistetyistä tiedostoista.
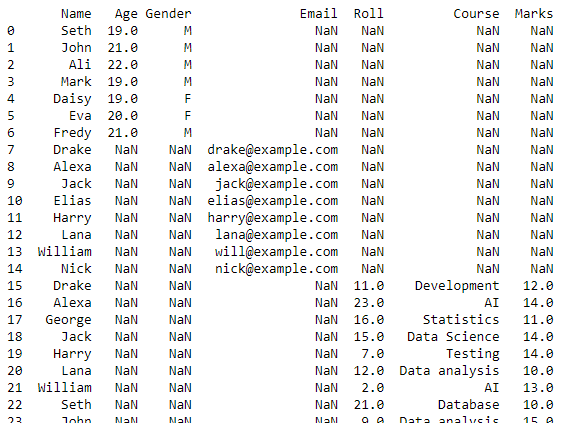
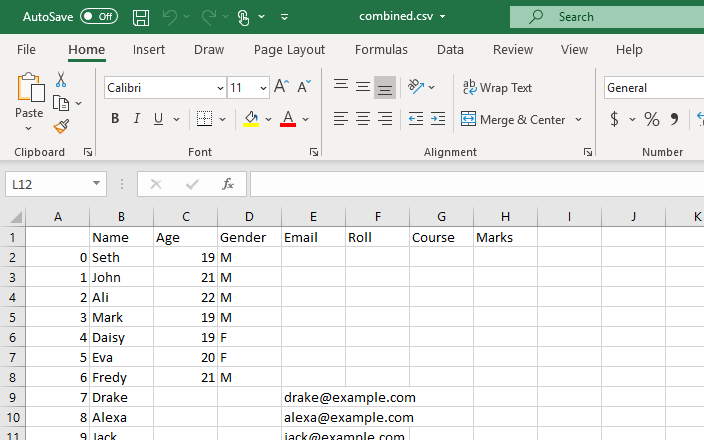
Tämä komentosarja palauttaa tietokehyksen, joka sisältää yhdistetyt tiedot kaikista työhakemistomme CSV-tiedostoista.
Tämä tietokehys muunnetaan CSV-tiedostoksi, ja to_csv()-funktiota käytetään tähän muuntamiseen. Tämä uusi CSV-tiedosto on yhdistetyt CSV-tiedostot, jotka on luotu kaikista nykyiseen työhakemistoon tallennetuista CSV-tiedostoista.
Johtopäätös
Tässä viestissä keskustelimme siitä, miksi meidän on yhdistettävä CSV-tiedostoja. Keskustelimme siitä, kuinka kaksi tai useampia CSV-tiedostoja voidaan yhdistää Pythonissa. Jaoimme tämän opetusohjelman kahteen osaan. Ensimmäisessä osassa selitimme, kuinka append()- ja concat()-funktioita käytetään yhdistämään CSV-tiedostoja, joilla on sama rakenne tai sarakkeiden nimi. Toisessa osassa käytimme merge()-menetelmää, os.path.join() ja glob-menetelmää eri sarakkeiden ja rakenteiden CSV-tiedostojen yhdistämiseen.