Tämä opas havainnollistaa, kuinka VectorStoreRetrieverMemorya käytetään LangChain-kehyksen avulla.
Kuinka käyttää VectorStoreRetrieverMemorya LangChainissa?
VectorStoreRetrieverMemory on LangChainin kirjasto, jota voidaan käyttää poimimaan tietoa/dataa muistista käyttämällä vektorivarastoja. Vektorikauppoja voidaan käyttää tietojen tallentamiseen ja hallintaan, jotta tiedot voidaan poimia tehokkaasti kehotteen tai kyselyn mukaan.
Jos haluat oppia VectorStoreRetrieverMemoryn käytön LangChainissa, käy läpi seuraava opas:
Vaihe 1: Asenna moduulit
Aloita muistin noutajan käyttö asentamalla LangChain pip-komennolla:
pip asennus langchain
Asenna FAISS-moduulit saadaksesi tiedot semanttisen samankaltaisuushaun avulla:
pip asentaa faiss-gpu 
Asenna chromadb-moduuli Chroma-tietokannan käyttöä varten. Se toimii vektorivarastona rakentamaan muistia noutajalle:
pip asennus chromadb 
Toinen moduuli tiktoken tarvitaan asennettavaksi, jota voidaan käyttää luomaan tokeneita muuntamalla tiedot pienemmiksi paloiksi:
pip asentaa tiktoken 
Asenna OpenAI-moduuli käyttääksesi sen kirjastoja LLM:ien tai chatbottien rakentamiseen sen ympäristön avulla:
pip install openai 
Järjestä ympäristö Python IDE:ssä tai muistikirjassa käyttämällä OpenAI-tilin API-avainta:
tuonti sinätuonti getpass
sinä . suunnilleen [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'OpenAI API Key:' )
Vaihe 2: Tuo kirjastot
Seuraava askel on hankkia kirjastot näistä moduuleista muistinnoutajan käyttöä varten LangChainissa:
alkaen langchain. kehotteita tuonti PromptTemplatealkaen treffiaika tuonti treffiaika
alkaen langchain. llms tuonti OpenAI
alkaen langchain. upotukset . openai tuonti OpenAIEembeddings
alkaen langchain. ketjut tuonti Keskusteluketju
alkaen langchain. muisti tuonti VectorStoreRetrieverMemory
Vaihe 3: Vector Storen alustaminen
Tämä opas käyttää Chroma-tietokantaa FAISS-kirjaston tuonnin jälkeen tietojen purkamiseen syöttökomennolla:
tuonti faissalkaen langchain. lääkärikauppa tuonti InMemoryDocstore
#kirjastojen tuonti tietokantojen tai vektorivarastojen määrittämistä varten
alkaen langchain. vektorivarastot tuonti FAISS
#luo upotuksia ja tekstejä tallentaaksesi ne vektorivarastoihin
embedding_size = 1536
indeksi = faiss. IndexFlatL2 ( embedding_size )
embedding_fn = OpenAIEembeddings ( ) . embed_query
vektorikauppa = FAISS ( embedding_fn , indeksi , InMemoryDocstore ( { } ) , { } )
Vaihe 4: Rakenna noutaja Vector Storen tukemana
Rakenna muistia tallentaaksesi keskustelun viimeisimmät viestit ja saadaksesi keskustelun kontekstin:
noutaja = vektorikauppa. noutajana ( search_kwargs = sanele ( k = 1 ) )muisti = VectorStoreRetrieverMemory ( noutaja = noutaja )
muisti. save_context ( { 'syöttö' : 'Tykkään syödä pizzaa' } , { 'lähtö' : 'fantastinen' } )
muisti. save_context ( { 'syöttö' : 'Olen hyvä jalkapallossa' } , { 'lähtö' : 'okei' } )
muisti. save_context ( { 'syöttö' : 'En pidä politiikasta' } , { 'lähtö' : 'varma' } )
Testaa mallin muistia käyttämällä käyttäjän antamaa syötettä ja sen historiaa:
Tulosta ( muisti. load_memory_variables ( { 'kehottaa' : 'mitä urheilua minun pitäisi katsoa?' } ) [ 'historia' ] ) 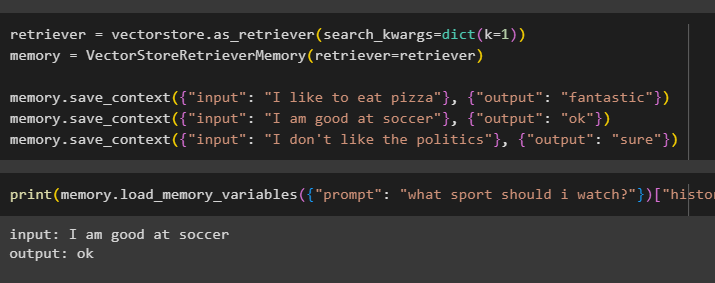
Vaihe 5: Noutajan käyttö ketjussa
Seuraava vaihe on muistinnoutajan käyttö ketjujen kanssa rakentamalla LLM OpenAI()-menetelmällä ja määrittämällä kehotemalli:
llm = OpenAI ( lämpötila = 0 )_DEFAULT_MALLINE = '''Se on vuorovaikutusta ihmisen ja koneen välillä
Järjestelmä tuottaa hyödyllistä tietoa yksityiskohtineen kontekstin avulla
Jos järjestelmällä ei ole vastausta sinulle, se vain sanoo, että minulla ei ole vastausta
Tärkeää tietoa keskustelusta:
{historia}
(jos teksti ei ole relevantti, älä käytä sitä)
Nykyinen chat:
Ihminen: {input}
AI: '''
PROMPT = PromptTemplate (
input_variables = [ 'historia' , 'syöttö' ] , sapluuna = _DEFAULT_MALLINE
)
#configure ConversationChain() käyttämällä sen parametrien arvoja
keskustelu_yhteenvedon kanssa = Keskusteluketju (
llm = llm ,
kehote = PROMPT ,
muisti = muisti ,
monisanainen = Totta
)
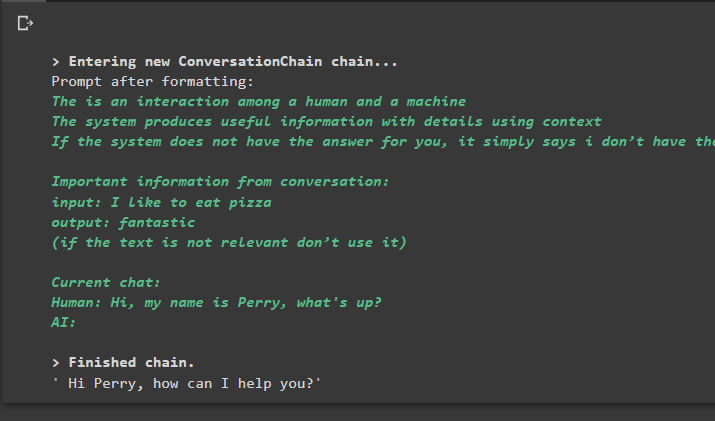
keskustelu_yhteenvedon kanssa. ennustaa ( syöttö = 'Hei, nimeni on Perry, mitä kuuluu?' )
Lähtö
Komennon suorittaminen ajaa ketjun ja näyttää mallin tai LLM:n antaman vastauksen:
Jatka keskustelua käyttämällä kehotetta, joka perustuu vektorikauppaan tallennettuihin tietoihin:
keskustelu_yhteenvedon kanssa. ennustaa ( syöttö = 'mikä on lempiurheiluni?' ) 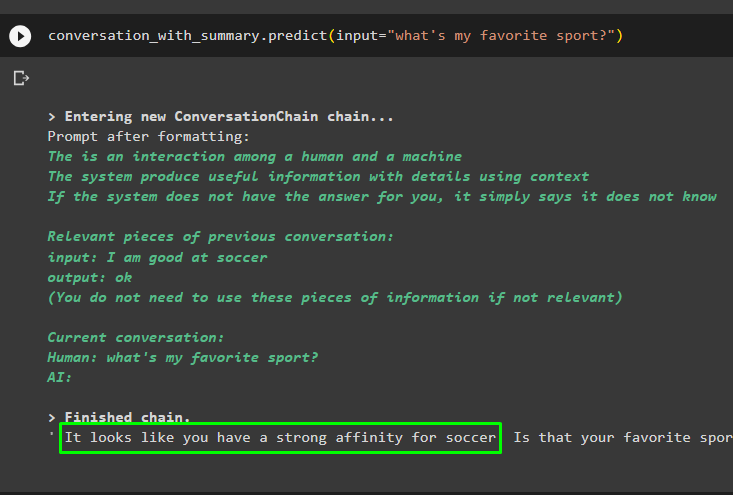
Aiemmat viestit tallentuvat mallin muistiin, jonka avulla malli voi ymmärtää viestin kontekstin:
keskustelu_yhteenvedon kanssa. ennustaa ( syöttö = 'Mikä on lempiruokani' ) 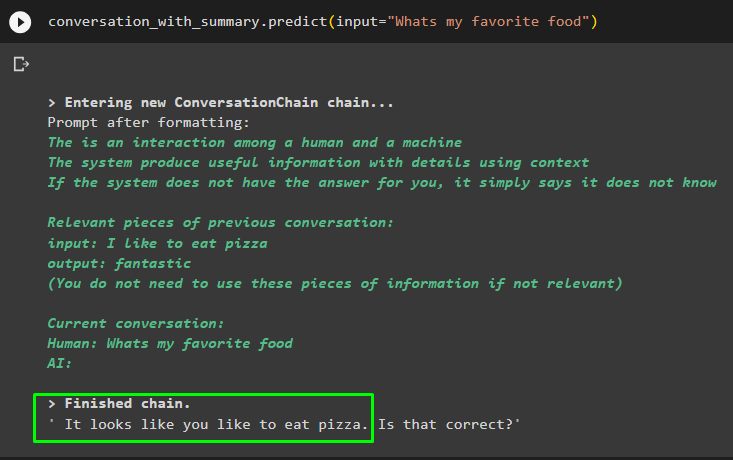
Hanki mallille annettu vastaus jossakin edellisistä viesteistä tarkistaaksesi, kuinka muistinnoutaja toimii chat-mallin kanssa:
keskustelu_yhteenvedon kanssa. ennustaa ( syöttö = 'Mikä on nimeni?' )Malli on näyttänyt tulosteen oikein käyttämällä samankaltaisuushakua muistiin tallennetuista tiedoista:
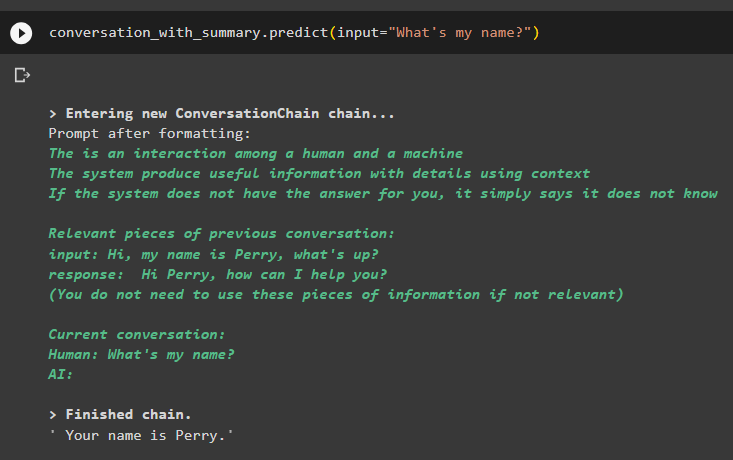
Siinä on kyse vektorivaraston noutajan käytöstä LangChainissa.
Johtopäätös
Jos haluat käyttää LangChainin vektorisäilöön perustuvaa muistinnoutajaa, asenna moduulit ja puitteet ja määritä ympäristö. Tuo sen jälkeen kirjastot moduuleista rakentaaksesi tietokanta Chroman avulla ja aseta sitten kehotemalli. Testaa noutaja tietojen tallentamisen jälkeen muistiin aloittamalla keskustelu ja esittämällä kysymyksiä edellisiin viesteihin liittyen. Tässä oppaassa on käsitelty VectorStoreRetrieverMemory-kirjaston käyttöprosessia LangChainissa.