Skaalautuvuus
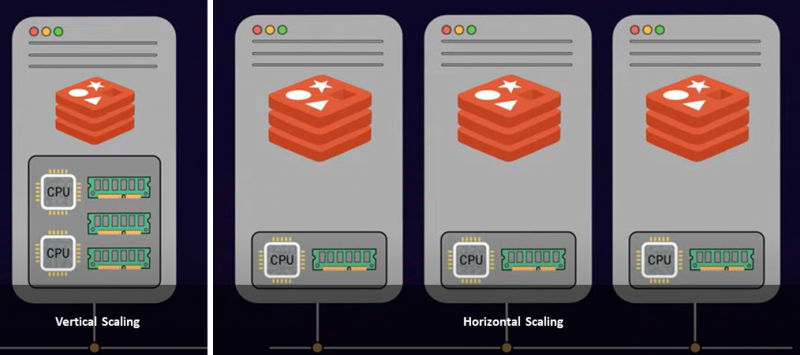
Palvelimen skaalaamiseen on kaksi yleistä lähestymistapaa: pystyskaalaus ja vaakasuora skaalaus. Pystysuuntainen skaalaus tai skaalaus lisää palvelimeesi tehoa ja resursseja, kuten enemmän suorittimia, muistia ja tallennustilaa, mikä on kallista. Toisaalta vaakasuuntainen skaalaus lisää useita solmuja olemassa olevaan resurssivalikoimaasi. Tätä kutsutaan skaalautumiseksi. Joten rajoitustesi ja vaatimustesi perusteella sinun on valittava yksi suurempi palvelinesiintymä tai ottaa käyttöön useita palvelinsolmuja.
Oletetaan, että sinulla on 100 Gt RAM-muistia ja tarvitset 200 Gt tietoa. Tässä tapauksessa sinulla on kaksi vaihtoehtoa:
- Skaalaa lisäämällä järjestelmään enemmän RAM-muistia
- Skaalaa lisää lisäämällä toinen palvelinesiintymä, jossa on 100 Gt RAM-muistia
Jos olet saavuttanut infrastruktuurisi enimmäismuistirajan, skaalaus on ihanteellinen lähestymistapa. Lisäksi skaalaus lisää tietokannan suorituskykyä valtavalla marginaalilla.
Redis Sharding
On tunnettu tosiasia, että Redis toimii yhdellä säikeellä. Joten Redis ei pysty käyttämään useita palvelimesi CPU:n ytimiä komentojen käsittelemiseen. Siksi lisäämällä enemmän prosessoriytimiä ei Redisillä saavuteta paljon suorituskykyä tai suorituskykyä. Tietosi jakaminen useiden palvelinilmentymien kesken ei pidä paikkaansa. Useiden palvelimien lisääminen ja tietojoukon jakaminen niiden kesken mahdollistaa asiakaspyyntöjen rinnakkaiskäsittelyn, mikä lisää läpimenoa. Lisäksi kokonaissuorituskyky voi kasvaa lähes lineaarisesti.
Tätä lähestymistapaa, jossa tiedot jaetaan tai jaetaan useiden palvelimien kesken skaalaus mielessä, kutsutaan sirpalointia . Kutsutaan kaikkia palvelimia, jotka tallentavat osia datasta sirpaleita .
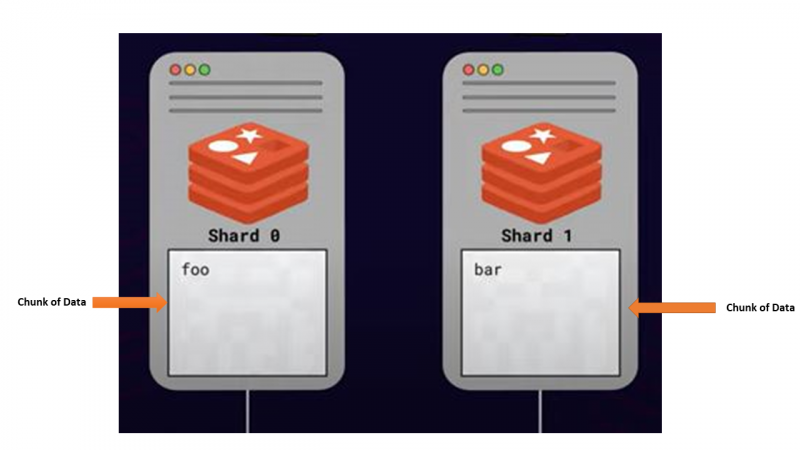
Kuinka jakaminen tapahtuu - Algoritminen jakaminen
Yksi tärkeimmistä jakamiseen liittyvistä huolenaiheista oli, kuinka tietty avain paikannettiin useiden Redis-solmujen joukosta. Koska tietty avain voidaan tallentaa mihin tahansa saatavilla olevaan sirpaleeseen, kaikkien sirpaleiden kyseleminen tietyn avaimen löytämiseksi ei ole paras vaihtoehto. Joten pitäisi olla tapa kartoittaa jokainen avain tiettyyn sirpaleeseen, ja Redis käyttää algoritmista sirpalointistrategiaa.
Yleisin tapa on laskea hash-arvo käyttämällä Redis-avaimen nimeä ja moduloa. Jaa se sitten käytettävissä olevilla Redis-sirpaleilla järjestelmässä.
HASH_SLOT = CRC16(avain) mod 16384Se on varsin hyvä ratkaisu, kunhan sirpaleiden kokonaismäärä on vakio. Aina kun lisäät uuden Reids-palvelinesiintymän, tuloksena oleva arvo tietylle avaimelle voi muuttua, koska sirpaleiden kokonaismäärä on kasvanut. Se lopulta kyselee väärää Redis-sirpaletta. Siksi sinun tulee seurata uudelleenjakoprosessia laskemalla uusi sirpale jokaiselle avaimelle ja siirtämällä tiedot oikealle palvelimelle, mikä on hankalaa eikä vähäpätöinen tehtävä, jos sirpaleiden kokonaismäärä kasvaa ajoittain.
Redis käyttää uutta loogista kokonaisuutta nimeltä a hash paikka tämän ongelman estämiseksi. Tietylle sirpaleelle on saatavana useita hajautuspaikkoja, ja yhteen hajautuspaikkaan voi mahtua useita Redis-avaimia. Redis-tietokantaklusterissa on 16384 hash-paikkaa, jotka pysyvät ennallaan. Modulo-jako tehdään hajautuspaikkojen määrällä sirpaleiden määrän sijaan. Se tarjoaa hajautuspaikan oikean sijainnin määritetylle avaimelle, vaikka sirpaleiden määrä on kasvanut. Se yksinkertaistaa uudelleenjakoprosessia siirtämällä hash-paikat yhdestä sirpaleesta uuteen, mikä jakaa tiedot eri Redis-esiintymien kesken vaatimusten mukaisesti.
Redis Shardingin edut
Redis-jako mahdollistaa useita etuja tietokantajärjestelmällesi minimaalisilla muutoksilla.
Korkea suorituskyky
Koska Redis on yksisäikeinen, useiden asiakaspyyntöjen käsittelyä ei voida käsitellä rinnakkain käyttämällä useita CPU-ytimiä. Joten uusien sirpaleiden tai palvelinesiintymien lisääminen takaa, että voit suorittaa Redis-toimintoja samanaikaisesti. Se lisää operaatioita sekunnissa Redis-tietokannassasi, mikä lopulta antaa sinulle korkean suorituskyvyn.
Korkea saatavuus
Sharing-lähestymistavan avulla Redis-klusteri voi määrittää master-replica-arkkitehtuurin, joka varmistaa korkean käytettävyyden ja kestävyyden.
Lue kopioita
Jakamisen avulla voit säilyttää tarkan kopion tiedoistasi ja suorittaa lukutoimintoja erillisten Redis-esiintymien kautta, mikä parantaa lukukyselysi suoritusta.
Näiden etujen lisäksi sirpalointi voi aiheuttaa aivojen jakautumista, kun Redis-klusterissa on parillinen määrä sirpaleita. Joten on suositeltavaa pitää Redis-klusterissasi pariton määrä sirpaleita.
Johtopäätös
Yhteenvetona voidaan todeta, että Redis sharding jakaa tiedot useiden palvelimien kesken, mikä mahdollistaa tietokannan skaalauksen ja suuren suorituskyvyn. Kuten mainittiin, Redis käyttää algoritmista jakostrategiaa osoittaakseen asiakkaan pyynnöt oikeaan sirpaleeseen. Tällä on joitain haittoja, kun sirpaleiden kokonaismäärä kasvaa. Joten sirpaleiden kokonaismäärän sijasta Redis laskee sopivan sirpaleen hash-paikkojen lukumäärän avulla. Jakamisen myötä Redis-tietokannat tarjoavat korkean käytettävyyden, korkean suorituskyvyn ja korkean suorituskyvyn.