'Pythonissa tietorakennetta, jota kutsutaan sanakirjaksi, käytetään tietojen tallentamiseen avain-arvo-pareina. Sanakirjaobjektit on optimoitu poimimaan tietoja/arvoja, kun avain tai avaimet tunnetaan. Muista, että sanakirjat voivat sisältää päällekkäisiä avaimia. Löytääksemme arvoja tehokkaasti vastaavan indeksin avulla, voimme muuntaa pandassarjan tai tietokehyksen, jossa on asiaankuuluva indeksi, sanakirjaobjektiksi, jossa on 'indeksi: arvo' avain-arvo-pareja. Tämän tehtävän saavuttamiseksi voidaan käyttää 'to_dict()' -menetelmää. Tämä toiminto on sisäänrakennettu toiminto, joka löytyy pandamoduulin Series-luokasta. Tietokehys muunnetaan python-luettelomaiseksi sarjojen datasanakirjaksi pandas.to_dict()-menetelmällä orient-parametrin määritetystä arvosta riippuen.
Kuinka muuntaa pandat Python-sanakirjaksi?
On olemassa useita tapoja muuntaa pandat sanakirjaksi. Pandas-tietokehyksen muuttamiseksi Python-sanakirjaksi käytämme kuitenkin Pandasissa to_dict()-menetelmää. Voimme suunnata palautetun sanakirjan avainarvo-pareja monin eri tavoin käyttämällä to_dict()-funktiota. Toiminnon syntaksi on seuraava:
Syntaksi
pandas.to_dict ( itä = 'sanella', sisään = )
Parametrit
suunta: Mihin tietotyyppeihin sarakkeet (sarjat) muunnetaan, määritetään merkkijonon arvolla ('dict', 'list', 'records', 'index', 'series', 'split'). Esimerkiksi avainsana 'luettelo' antaisi python-sanakirjan luetteloobjekteista, joissa on avaimet 'Sarakkeen nimi' ja 'Lista' (muunnettu sarja).
osaksi: luokka, voidaan läpäistä esiintymänä tai varsinaisena luokkana. Esimerkiksi luokan ilmentymä voidaan välittää oletuskäskyn tapauksessa. Parametrin oletusarvo on sanelu.
Palautustyyppi: Tietokehyksestä tai sarjasta muunnettu sanakirja.
Esimerkki # 01: Pandas-tietokehyksen muuntaminen sanakirjaksi
Käyttämällä pd.DataFrame()-funktion listaluetteloita luomme perustietokehyksen, jossa on joitakin sarakkeita ja rivejä, jotta voimme myöhemmin muuntaa sen python-sanakirjaksi.
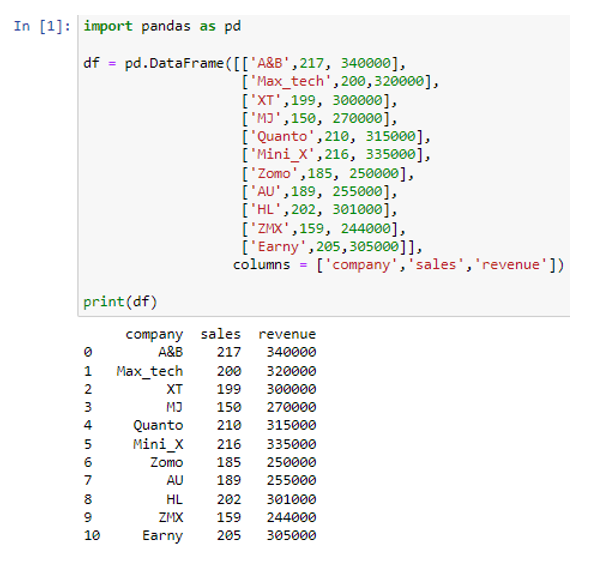
Olemme luoneet tietokehyksemme välittämällä luettelon pd.DataFrame()-funktion sisällä. Yllä olevassa tietokehyksessä on kolme saraketta 'yritys', 'myynti' ja 'tulo'. Sarakeyhtiöön olemme tallentaneet satunnaisten yritysten nimet ('A&B', 'Max_tech', 'XT', 'MJ', 'Quanto', 'Mini_X', 'Zomo', 'AU', 'HL') , 'ZMX', 'Earny'), sarake 'myynti' edustaa kunkin yrityksen myyntiä muodossa ('217', '200', '199', '150', '210', '216', '185' ”, '189', '202', '159', '205' ja sarake 'tulot' tallentaa arvot, jotka edustavat kunkin yrityksen tuottoa suhteessa vastaavaan myyntiin (340000 320000 300000 270000 315000 0 315000 335000 315000 335000 5 001 305 000). Nyt muunnamme tietokehyksemme 'df' python-sanakirjaksi.
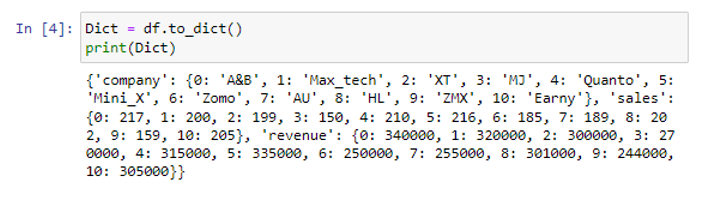
Soveltamalla to_dict()-menetelmää df-tietokehykseen olemme muuntaneet panda-tietokehyksen sanakirjaksi.
Esimerkki # 02: CSV-tiedostosta luodun Pandas-tietokehyksen muuntaminen sanakirjaksi
Esimerkissä # 1 loimme tietokehyksen käyttämällä luettelon sisällä olevia monikkoja. Nyt luomme tietokehyksen CSV-tiedoston avulla ja muutamme sen sitten sanakirjaksi to_dict()-funktiolla.
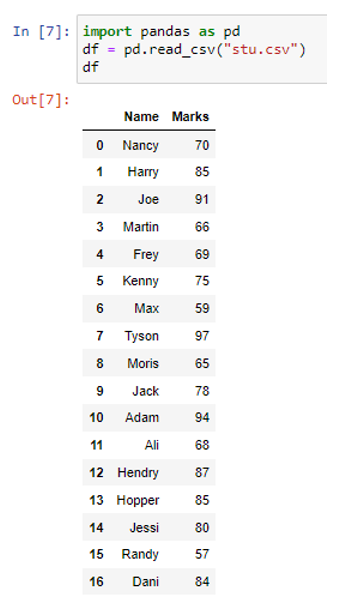
Tiedoston lukemiseen tietokehyksenä olemme käyttäneet pd.read_csv()-funktiota. Yllä olevassa tietokehyksessä meillä on kaksi saraketta (nimi ja merkit) ja seitsemäntoista riviä (0 - 16). Nyt käytämme menetelmää to_dict().
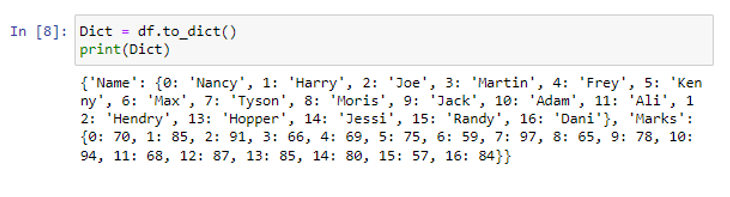
Funktio on muuttanut tietokehyksemme 'df' python-sanakirjaksi.
Esimerkki # 03: Muunna Pandas Dataframe arvoluettelot sisältäväksi sanakirjaksi
Aiemmissa esimerkeissä olemme muuntaneet pandat python-sanakirjaksi, joka sisältää useita sanakirjoja. Kun tietokehys muunnetaan sanakirjaobjektiksi, sarakkeiden otsikoiden tulee toimia sanakirjan avaimina, ja kaikki sarakkeiden tiedot tai arvot tulee lisätä tuloksena olevaan sanakirjaan kunkin avaimen arvoluettelona.
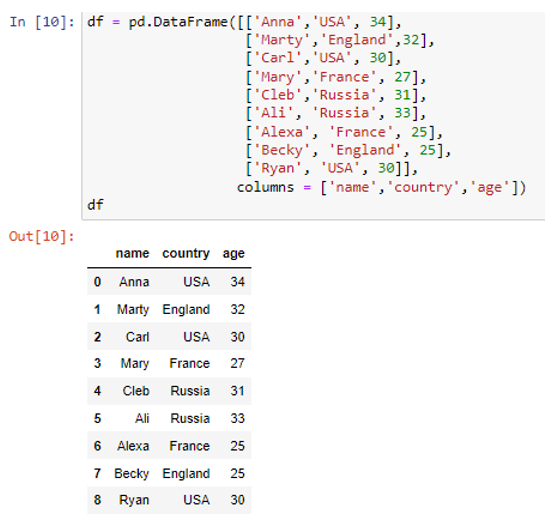
Olemme luoneet tietokehyksen, jossa on kolme saraketta 'nimi', 'maa' ja 'ikä'. Sarakkeeseen 'nimi' olemme tallentaneet tietoarvot ('Anna', 'Marty', 'Carl', 'Mary', 'Cleb', 'Ali', 'Alexa', 'Becky', 'Ryan') . Muut sarakkeet maa ja ikä ovat vahvoja arvoja kuten ('USA', 'Englanti', 'USA', 'Ranska', 'Venäjä', 'Venäjä', 'Ranska', 'Englanti', 'USA') ja ( 34, 32, 30, 27, 31, 33, 35, 25, 30) vastaavasti. Luomme luettelot sisältävän sanakirjan käyttämällä 'list'-parametria to_dict()-menetelmän sisällä.
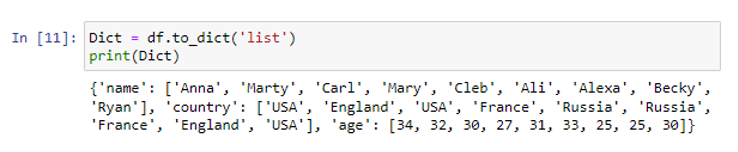
Käyttämällä listaparametria argumenttina to_list()-funktion sisällä, olemme luoneet useita listoja sisältävän sanakirjan.
Esimerkki # 03: Muunna Pandas Dataframe arvosarjan sisältäväksi sanakirjaksi
Kun DataFrame on muutettava sanakirjaksi, sarakkeen nimi toimii sanakirjan avaimina ja riviindeksi ja sarakkeen tiedot sanakirjan vastaavien avainten arvona.
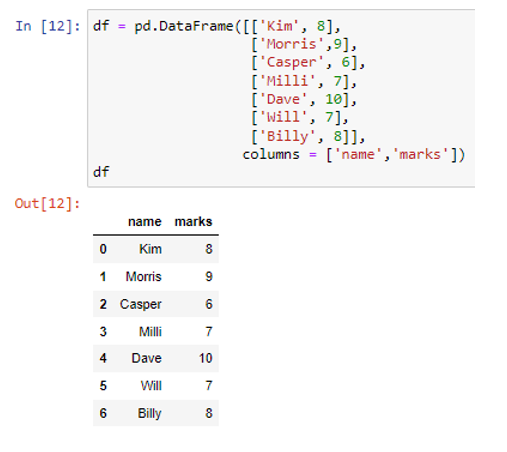
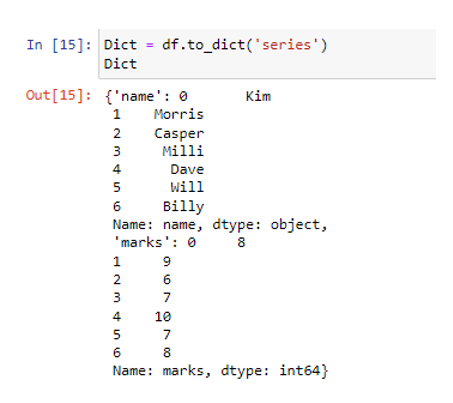
Olemme luoneet vaaditun datakehyksen pd.DataFrame() -menetelmällä. Äskettäin luodussa tietokehyksessä on kaksi saraketta. Nimisarake tallentaa tietoarvot merkkijonona ('Kim', 'Morris', 'Casper', 'Milli', 'Dave', 'Will', 'Billy'), kun taas merkkisarakkeet koostuvat numeerisista tiedoista kuten ( 8, 9, 6, 7, 10, 7, 8). Käytämme parametria 'series' merkkijonona to_dict()-funktion sisällä.
Esimerkki # 04: Muunna Pandas Dataframe sanakirjaksi ilman indeksiä ja otsikkoa
To_dict()-funktion parametria 'split' voidaan käyttää tietojen poimimiseen DataFrame-kehyksestä ilman sarakkeiden otsikoita tai kun meidän on poistettava otsikko- ja riviindeksi tiedoista. Sarakeotsikot, rivihakemisto ja todelliset tiedot jaetaan kolmeen osaan tätä parametria käyttämällä. Luodaan tietokehys, jotta voimme jakaa sen kolmeen osaan samalla kun muunnamme sen sanakirjaksi.
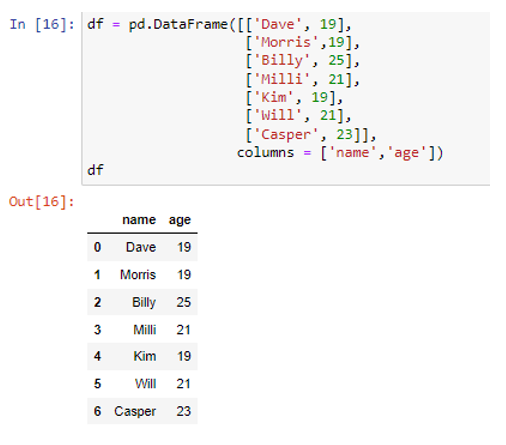
Olemme luoneet kaksi saraketta otsikoilla 'nimi' ja 'ikä', jotka sisältävät arvoja ('Dave', 'Morris', 'Billy', 'Milli', 'Kim', 'Will', 'Casper') ja (19, 19). , 25, 21, 19, 21, 23) vastaavasti. Muunnetaan ne python-sanakirjoiksi.

Avaimen 'data' avulla voimme hakea tiedot tuloksena olevasta sanakirjasta ilman hakemistoa tai otsikkoa.

Esimerkki # 05: Muunna Pandas Dataframe sanakirjaksi rivin ja riviindeksin mukaan
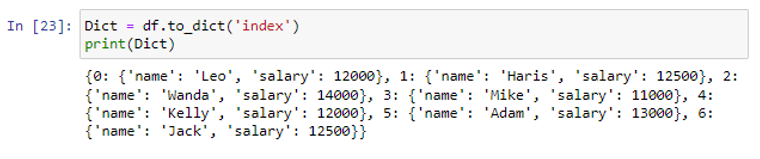
Parametria 'record' voidaan käyttää to_dict()-funktion sisällä tallentamaan kunkin tietokehyksen rivin tiedot useisiin erillisiin sanakirjaobjekteihin luettelon sisällä tai kun tarvitaan rivikohtaista tietoa. Sanakirjaobjekteja sisältävä luettelo palautetaan. Sanakirja, jonka avaimena on sarakkeen otsikko ja jokaisen rivin arvona saraketiedot.
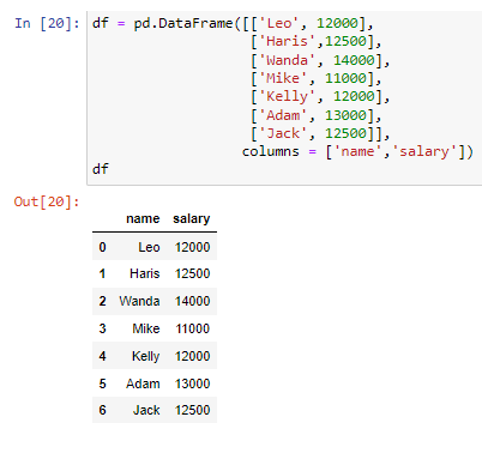
Olemme luoneet tietokehyksen, jossa on sarakkeet 'nimi' ja 'palkka'. Sarake 'nimi' sisältää tietoarvot ('Leo', 'Haris', 'Wanda', 'Mike', 'Kelly', 'Adam', 'Jack') ja palkkasarake tallentaa arvot (12000, 12500). , 14000, 11000, 12000, 13000, 12500). Luodaan nyt luettelo, jossa on useita python-sanakirjoja, jotka sisältävät kunkin rivin tiedot.

Indeksiparametria voidaan käyttää myös muuntamaan kunkin rivin tiedot tietokehyksestä sanakirjaksi. Palautetaan luettelo sanakirjan kohteista. Jokainen rivi luo sanakirjan. Missä riviindeksi on avain ja arvo on datasanakirja ja sarakenimike.
Johtopäätös
Tässä opetusohjelmassa olemme keskustelleet siitä, kuinka voimme muuntaa tietokehyksen tai panda-objektit python-sanakirjaksi. Olemme nähneet to_dict()-funktion syntaksin ymmärtääksemme tämän funktion parametrit ja kuinka voit muokata funktion lähtöä määrittämällä funktion eri parametreilla. Tämän opetusohjelman esimerkeissä olemme käyttäneet to_dict()-menetelmää, sisäänrakennettua pandasfunktiota, muuttamaan pandas-objektit python-sanakirjaan.