Katsotaanpa nyt Linuxin iconv-apuohjelmaa sen päätekonsolissa. Joten olemme suorittaneet käskyä 'iconv' lipulla '-l' näyttääksemme kaikki tunnetut ja eniten käytetyt koodatut merkistöt päätenäytöllämme. Se näyttää koodatut merkistöt sekä niiden aliakset. Näet pitkän luettelon koodatuista merkistöistä, kun olet vierittänyt alaspäin.
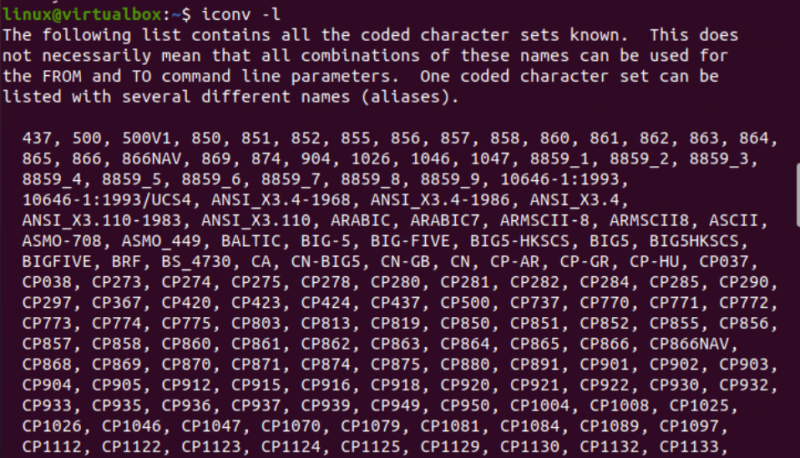
Nyt on aika aloittaa iconv-komennon toteuttaminen Linuxissa. Ensinnäkin tarvitsemme järjestelmäämme eri tyyppisiä tiedostoja muuntaaksemme yhden tyyppisen tiedostotyypin toiseksi. Näin ollen käytämme 'touch'-kyselyä konsolipäätteessä kolmen eri tiedoston luomiseen, eli Java-tyypin, C-tyypin ja tekstityypin. Listaamalla nykyisen hakemiston sisällön löydät sieltä äskettäin luodut tiedostot.
Tämän jälkeen tarkastelemme kunkin tiedoston tyyppiä erikseen käyttämällä 'tiedosto'-kyselyä yhdessä kunkin tiedoston nimen kanssa. Tämä kysely tarvitsee '-I'-vaihtoehdon näyttääkseen kunkin tiedoston koodausmerkistön tyypin erikseen. Jos unohdit käyttää '-I' -vaihtoehtoa, käytä sen sijaan '-mime' -lippua. Sekä '-I' ja '-mime' -liput toimivat samalla tavalla.
Nyt, kun suoritimme 'txt'-tyyppisen tiedoston 'file'-käskyn, saimme 'US-ASCII'-merkkityypin koodauksen. Vaikka käytetään samaa ohjetta Java- ja C-tiedostoille, se osoittaa, että molemmat tiedostot sisältävät 'BINARY'-merkkityyppisen koodauksen. Tämän lisäksi tämä ohje osoittaa, että kaikki nämä kolme tiedostoa ovat tyhjiä.
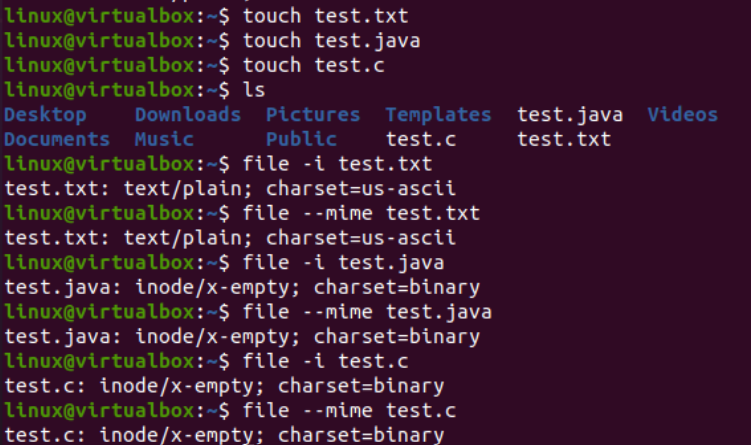
Nyt kuvaamme iconv-käskyn käyttöä konsolissa tietyn merkistökoodaustiedoston muuntamiseksi toiseksi merkistökoodaukseksi. Ennen sitä meidän on lisättävä tiedostoihimme koodia tai tietoja. Siksi olemme lisänneet Java-koodin 'text.java'-tiedostoon, C-koodin 'text.c'-tiedostoon ja lisänneet tekstidataa 'test.txt'-tiedostoon. Cat-kyselyä käytettiin tässä näyttämään kaikkien kolmen tiedoston sisältö alla esitetyllä tavalla:
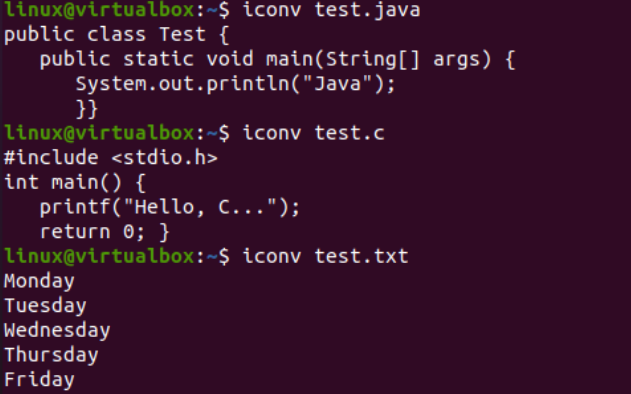
Nyt kun olemme lisänneet tiedot onnistuneesti, näemme näiden tiedostojen merkistökoodauksen jälleen. Joten olemme kokeilleet samaa tiedostokäskyä komentotulkin sisällä '-I'-lipulla ja tiedostonimillä, eli test.txt, test.java ja test.c. Näiden kolmen ohjeen suorittaminen erikseen kaikille kolmelle tiedostolle osoittaa, että merkistökoodaus on päivitetty Java- ja C-tiedostoille, mutta tekstitiedosto on pysynyt samana, eli US-ASCII. Java- ja C-tiedostojen koodaus oli aiemmin 'binäärinen'; nyt se on 'US-ASCII'. Se osoittaa myös, että tekstitiedosto sisältää pelkkää tekstidataa, kun taas kaksi muuta kooditiedostoa sisältävät skriptit sisältönä.

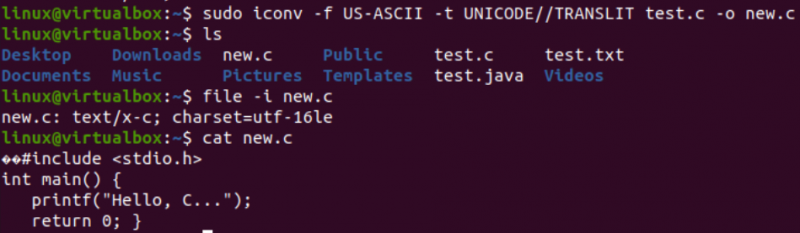
On aika suorittaa varsinainen tässä artikkelissa tarvittava tehtävä, eli muuntaa yksi koodaus toiseksi käyttämällä komentotulkin iconv-komentoa. Siten olemme käyttäneet komentotulkkipäätteessä 'iconv'-käskyä 'sudo'-oikeuksilla. Tämä komento tarkoittaa '-f'-vaihtoehtoa 'from' ja '-t' tarkoittaa 'to', eli yhdestä koodauksesta toiseen.
'-f'-vaihtoehdon jälkeen sinun on määritettävä koodaus, joka tiedostossasi on jo, eli US-ASCII. '-t'-vaihtoehdon jälkeen sinun on määritettävä koodaus, jonka haluat korvata vanhalla koodauksella, eli UNICODE. Sinun on määritettävä lähteenä käytettävän tiedoston nimi -o-vaihtoehdolla luodaksesi sen objektikuvan. Objektikuva olisi toinen tiedosto, eli 'new.c', samaa tyyppiä, mutta uudella koodauksella ja samalla tiedolla.
Kun olet suorittanut seuraavan käskyn, saat uuden tiedoston samaan hakemistoon, eli 'ls'-kyselyn mukaan. Nyt tarkistamme uuden tiedoston merkistökoodauksen, joka on luotu käyttämällä iconv-ohjetta. Käytämme jälleen 'file'-käskyä '-I'-vaihtoehdon ja uuden tiedostonimen kanssa, eli new.c.
Näet, että tämän uuden tiedoston merkistö on erilainen kuin vanhan tiedoston merkistö, eli UTF-16LE-merkistö. Tämä johtuu siitä, että olemme kääntäneet US-ASCII-koodauksen UNICODE-koodaukseksi käyttämällä new.c-tiedostomme iconv-ohjetta. 'Kissa'-kysely näytti saman C-koodin tiedostossa, mutta alkoi joillain Unicode-merkeillä, kuten jo esitettiin.
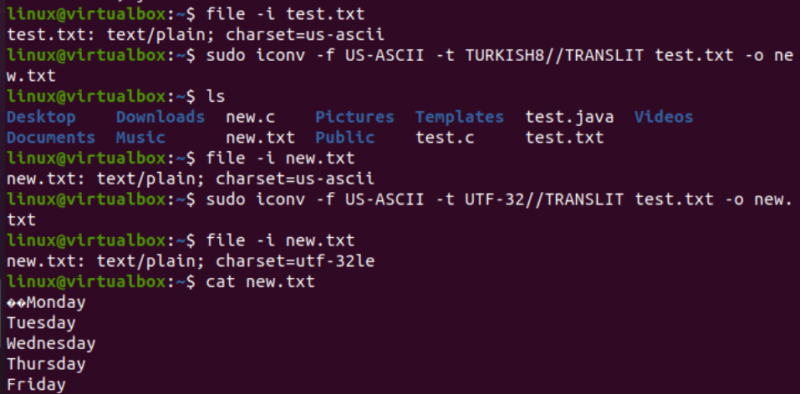
Hyvin samalla tavalla muutamme test.txt-tekstitiedoston koodausta. Tiedoston ohje osoittaa, että siinä on US-ASCII-merkistökoodaus. iconv-komentoa on käytetty samassa muodossa test.txt-tiedoston koodauksen muuntamiseen US-ASCII-muodosta TURKISH8-muotoon. Näet, että se ei muuta US-ASCII:ta turkkiksi.
Tämän jälkeen käytimme samaa komentoa kattamaan US-ASCII-UTF-32-merkistökoodauksen samalle tiedostolle. Tällä kertaa se toimii. Tämä johtuu siitä, että joskus voi olla ongelmia yhden koodausjoukon muuntamisessa toiseksi tai toinen koodaus ei ehkä tue sitä.
Johtopäätös
Tässä artikkelissa käsiteltiin, kuinka iconv Linux-ohjeiden avulla muunnetaan yksi koodausmerkkisarja toiseksi käyttämällä niiden aliaksia. Tällä tavalla meidän piti luoda joitain erityyppisiä tiedostoja.