'Pandas' on tehokas työkalu python-ympäristöön. Se on 'avoin' lähdekoodi tietojen analysointiin. Pandaliitos- ja pandojen yhdistämismenetelmää käytetään kahden tietokehyksen yhdistämiseen yhdeksi tietokehykseksi. Molemmissa pandamenetelmissä ero on siinä, että pandat 'join' -funktio yhdistää tietokehyksen indeksin avulla. Panda-toiminto yhdistää tietokehyksen indeksin ja sarakemenetelmän avulla, jolloin voimme valita halutun sarakkeen itse. Pandojen yhdistämismenetelmää käytetään enimmäkseen pandojen yhdistämismenetelmään verrattuna. Toteuttamiseen käytettävä ohjelmisto on 'spyder'-ohjelmisto, joka on python-ympäristössä ja tarjoaa meille etuja pandas join method()- ja pandas merge()-metodifunktion kooditoteutukseen.
Pandas Join() -menetelmän syntaksi
'df1. liittyä seuraan ( df2 ) ”Yllä olevan syntaksin 'df' on lyhenne sanoista 'dataframe'. Syntaksissa on kaksi datakehystä, joissa on 'dot join' -funktio, joka on tarkoitettu menetelmän kutsumiseen. Se on panda-menetelmä kahden tietokehyksen yhdistämiseksi. Se toimii indeksin avulla yhdistämään tietokehykset yhdeksi kehykseksi.
Pandas Merge() -menetelmän syntaksi
'df1. yhdistää ( df2 , päällä = 'sarakkeen_nimi' ) ”Pandan yhdistämismenetelmän syntaksissa on kaksi datakehystä 'df1' ja 'df2'. 'Pisteyhdistys'-toiminto kutsuu menetelmän yhdistää molemmat tietokehykset sarakkeiden ulkonäölle käänteisesti.
Käsittelemme seuraavia tapoja yhdistää kaksi tietokehystä käyttääksemme pandayhdistely- ja pandaliitosmenetelmiä:
- Pandas Join menetelmä päällekkäin.
- Pandat liittyvät menetelmään indeksin nollauksella.
- Pandan yhdistämismenetelmä (sarake 'vasen ja oikea').
- Pandan yhdistämismenetelmä eksplisiittinen.
Tietokehysten luominen Pandas Merge- ja Pandas Join -menetelmän toteuttamista varten
Ensin meidän on luotava tietokehys. Tätä varten käytämme 'spyder' -työkalua. Kun olet avannut sen, aloita koodin kirjoittaminen. Tuo pandat 'pd'-muodossa pandakirjastoyhdistykseen. Meillä on datakehysmuuttujat 'x', 'y', 'p' ja 'q vastaavasti ja 'a' arvoilla '1' ja 'b' arvolla '2'.

Tulos on 'df', joka on luotu määritetyillä arvoilla. Voimme tehdä siitä niin suuren kuin data on.
Toisen tietokehyksen luominen
Meidän on tehtävä toinen tietokehys ymmärtääksemme selkeästi pandojen yhdistämis- ja sulautumismenetelmät. Täällä meillä on 'df' luotu sama kuin yllä oleva 'df', vain määritetyt muuttujat ovat erilaisia. Meillä on 'h', 'j', 's' ja 'd', kun taas määritä arvot 'b' arvolla '8' ja 'Y' arvolla '3'.

Tulos näyttää yksinkertaisen luodun 'df':n.

Esimerkki # 01: Pandan liittymismenetelmä (päällekkäinen)
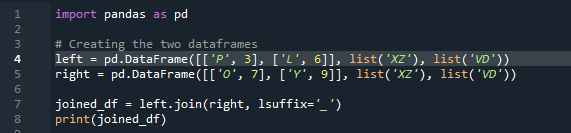
Nyt näemme kuinka yhdistää kaksi datakehystä pandaliitosmenetelmällä. Tätä menetelmää varten voimme valita tietokehyksestä haluamasi sarakkeen, jota haluamme käsitellä. Olemme ottaneet esimerkin päällekkäisestä sarakkeesta 'vasemmalla' 'df:stä', joten voimme korjata tämän 'liitteellä' tietojen päällekkäisyyden voittamiseksi. Tässä käytetyt muuttujat ovat 'x', 'z', 'v', 'd'. 'p', 'o', 'l' ja 'y' arvoilla '3', '6', '7' ja '9'. '.join' kutsuu menetelmää, ja tasaus on asetettu vasemmalle liitos oikealla 'df'-liitteellä. ”. Koodissa käytetty 'liite' johtuu siitä, että tietokehyksessä on kaksi saraketta, joilla on sama nimi, joka on 'avain' ja jotka eivät mene päällekkäin tietojen kanssa.
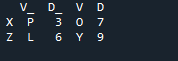
Tulos ei näytä päällekkäisiä tietoja menetelmällä, jossa kaksi 'df' yhdistetään pandaliitosmenetelmällä.
Esimerkki # 02: Pandan liittymismenetelmä indeksin nollausta käyttämällä
Tässä esimerkissä määritämme erikseen sarakkeen, jossa on parametri 'on', jota käytetään 'avaimena' menetelmäliitännässä, joka auttaa yhdistämään kaksi datakehystä. yhdistetty asia tehdään tällä parametrilla. Myös toisen 'df':n indeksin tulee olla samanlainen, jotta ne voidaan yhdistää. Samanlaisia tietoja tai samaan tarkoitukseen käytettyjä tietoja voidaan käsitellä yhdessä. Tämä käyttää hakemistoa edelleen, käyttämällä oikealta. Muuttujat ovat 's', 't', 'u', 'v', 'n', 'w', 'k' ja 'q'. Annetut arvot ovat '3', '6', '7' ja '9'. 'Reset dot index' on pandojen tapa nollata 'df'-indeksi. Nollausindeksi asettaa kaikki tietokehysluettelosi kokonaisluvut 0:sta siihen asti, kunnes datakehystietoja on pidennetty.
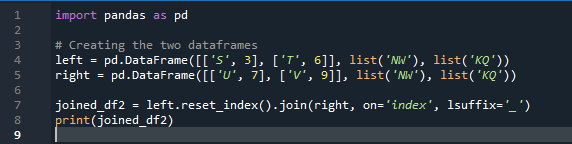
Tässä on tulos, joka näytetään pandan indeksillä 'avain' -liitosmenetelmällä.
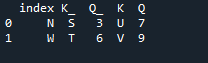
Esimerkki # 03: Pandan yhdistämismenetelmä (sarake 'vasen ja oikea')
Yhdistämismenetelmä suorittaa samanlaisen toiminnon kuin pandaliitosmenetelmä. Molemmat menetelmät on tarkoitettu tietojen yhdistämiseen samanlaisessa tietokehyksessä. Yhdistämismenetelmä on monipuolisempi ja vaatii avaimen määrittämistä. Voimme myös määrittää sen vasemmalle ja oikealle sarakkeelle tietokehyksesi työstä riippuen. Koodin muuttujat ovat 's', 'd', 'g', 'f', 'k', 'j', 'b' ja 'q'. määritetyt arvot ovat '9', '5', '6' ja '7'. Ulompi 'join' -toteutus tehdään molemmille 'df' -malleille käyttämällä panda-yhdistysmenetelmäfunktion parametria 'how'.
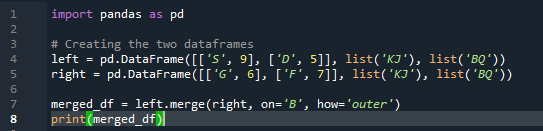
Näkemämme tulos näyttää kahden tietokehyksen yhdistetyt tiedot. 'NaN' tarkoittaa 'ei numeroa', mikä tarkoittaa, että jos tiedoissa ei ole numeroa, 'NaN' näkyy siellä.
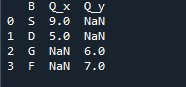
Esimerkki # 04: Yhdistämismenetelmä nimenomaisesti
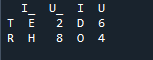
Tässä, tässä esimerkissä, yhdistämismenetelmä on indeksin tuhoaminen, eikä indeksiarvoa ole oletettu tietokehyksessä. Suoritamme tämän menetelmän tehtävän työn mukaan, jolloin nimenomaan on seurattava. Se yhdistää vasemman tai oikeanpuoleiseen indeksiin perustuvat tiedot parametriin. Tämän tietokehyksen muuttujat ovat 't', 'r', 'I', 'u', 'h', 'o', 'e' ja 'e'. Annetut arvot ovat '2', '4', '6' ja '4'. Yllä oleva esimerkki panda-yhdistämismenetelmästä sarakkeiden valinnalla tarpeen mukaan on edustavin ja arvokkain tapa yhdistää kaksi datakehystä. Tarkistetaan koodirivin lopussa, onko yhdistämisavain ainutlaatuinen tietojoukossa.
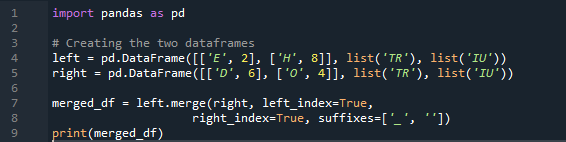
Alla olevassa lähdössä indeksiä ei näytetä ilman indeksiä, vaan toiminto suoritetaan oikean ja vasemman indeksin perusteella.
Johtopäätös
Merge()- ja join()-menetelmät ovat molemmat erittäin käteviä ja tehokkaita menetelmiä. Molempia näitä toimintoja käytetään kahden erillisen datakehyksen yhdistämiseen samassa tietokehyksessä, mutta niillä on eri käyttötapa tapauksesta riippuen. Tässä artikkelissa olemme oppineet tärkeimmät erot pandan liittymis- ja yhdistämismenetelmän välillä. Esimerkit tehtyä ja pandaliitosmenetelmän ymmärtämisen jälkeen päätämme sen tiedolla, että jos haluamme joustavampaa ja tietokantatyyppistä liittämistä, on parempi käyttää pandojen yhdistämismenetelmää. Toisaalta, jos haluamme tehdä datakehyksen yhdistämisen indeksin kanssa laajasti, voimme käyttää pandas join() -metodifunktiota.