Esimerkki 1: DataFramen lajittelu Order()-menetelmällä R:ssä
R:n order()-funktiota käytetään lajittelemaan DataFrames yhden tai useamman sarakkeen mukaan. Järjestysfunktio hankkii lajiteltujen rivien indeksit DataFramen rivien järjestämiseksi uudelleen.
emp = tiedot. kehys ( nimet = c ( 'Andy' , 'Mark' , 'Bonnie' , 'Caroline' , 'John' ) ,ikä = c ( kaksikymmentäyksi , 23 , 29 , 25 , 32 ) ,
palkkaa = c ( 2000 , 1000 , 1500 , 3000 , 2500 ) )
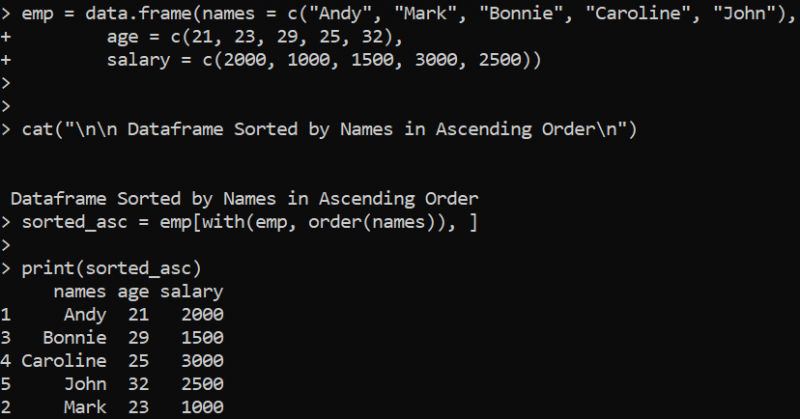
kissa ( ' \n \n Tietokehys lajiteltu nimien mukaan nousevaan järjestykseen \n ' )
lajiteltu_nouseva = emp [ kanssa ( emp , Tilaus ( nimet ) ) , ]
Tulosta ( lajiteltu_nouseva )
Tässä määrittelemme 'emp' DataFramen kolmella sarakkeella, jotka sisältävät erilaisia arvoja. Cat()-funktiota käytetään tulostamaan käsky, joka osoittaa, että 'emp' DataFrame 'names'-sarakkeessa nousevassa järjestyksessä lajitellaan. Tätä varten käytämme R:n order()-funktiota, joka palauttaa nousevaan järjestykseen lajiteltujen arvojen indeksipaikat. Tässä tapauksessa with()-funktio määrittää, että 'names'-sarake tulee lajitella. Lajiteltu DataFrame tallennetaan 'sorted_asc'-muuttujaan, joka välitetään argumenttina print()-funktiossa lajiteltujen tulosten tulostamiseksi.
Tästä syystä DataFramen lajitellut tulokset 'names'-sarakkeen mukaan nousevassa järjestyksessä näytetään seuraavassa. Saadaksesi lajittelutoiminnon laskevassa järjestyksessä, voimme vain määrittää negatiivisen merkin sarakkeen nimellä edellisessä order()-funktiossa:
Esimerkki 2: DataFramen lajittelu Order()-menetelmän parametrien avulla R:ssä
Lisäksi order()-funktio käyttää laskevia argumentteja DataFramen lajitteluun. Seuraavassa esimerkissä määritämme order()-funktion argumentilla lajittelemaan kasvavaan tai laskevaan järjestykseen:
df = tiedot. kehys (
id = c ( 1 , 3 , 4 , 5 , 2 ) ,
tietenkin = c ( 'Python' , 'Java' , 'C++' , 'MongoDB' , 'R' ) )
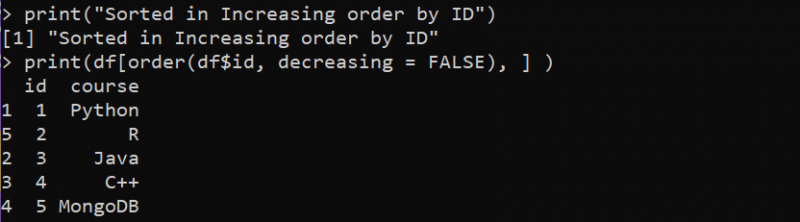
Tulosta ( 'Lajiteltu laskevaan järjestykseen tunnuksen mukaan' )
Tulosta ( df [ Tilaus ( df$id , vähenee = TOTTA ) , ] )
Tässä ilmoitamme ensin 'df'-muuttujan, jossa data.frame()-funktio määritellään kolmella eri sarakkeella. Seuraavaksi käytämme print()-funktiota, jossa tulostamme viestin osoittamaan, että DataFrame lajitellaan laskevaan järjestykseen 'id'-sarakkeen perusteella. Tämän jälkeen otamme uudelleen käyttöön print()-funktion lajittelun suorittamiseksi ja tulosten tulostamiseksi. Print()-funktion sisällä kutsumme 'order'-funktiota lajittelemaan 'df' DataFrame -sarakkeen 'course' perusteella. Argumentti 'lasku' asetetaan arvoon TOSI, jotta se lajitellaan laskevaan järjestykseen.
Seuraavassa kuvassa DataFramen 'id'-sarake on järjestetty laskevaan järjestykseen:

Kuitenkin saadaksemme lajittelutulokset nousevassa järjestyksessä, meidän on asetettava order()-funktion laskeva argumentti arvolla FALSE, kuten seuraavassa esitetään:
Tulosta ( 'Lajiteltu kasvavaan järjestykseen tunnuksen mukaan' )Tulosta ( df [ Tilaus ( df$id , vähenee = VÄÄRÄ ) , ] )
Siellä saamme DataFramen lajitteluoperaation tulos 'id'-sarakkeella nousevassa järjestyksessä.
Esimerkki 3: DataFramen lajittelu Arrange()-menetelmällä R:ssä
Lisäksi voimme myös käyttää arrange()-menetelmää DataFrame-kehyksen lajitteluun sarakkeiden mukaan. Voimme myös lajitella nousevaan tai laskevaan järjestykseen. Seuraava annettu R-koodi käyttää arrange()-funktiota:
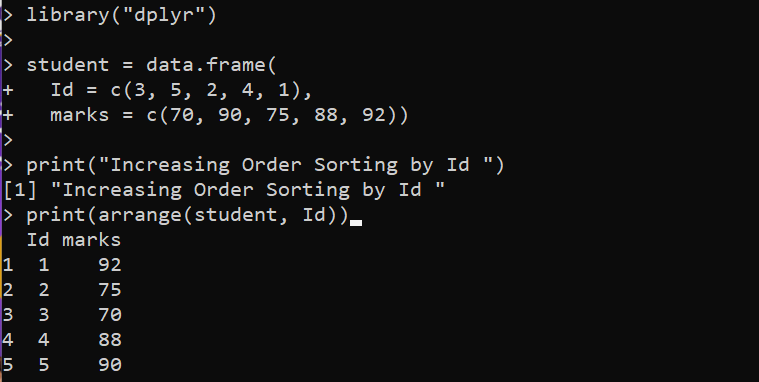
kirjasto ( 'dplyr' )opiskelija = tiedot. kehys (
Id = c ( 3 , 5 , 2 , 4 , 1 ) ,
merkit = c ( 70 , 90 , 75 , 88 , 92 ) )
Tulosta ( 'Kasvava tilauslajittelu tunnuksen mukaan' )
Tulosta ( järjestää ( opiskelija , Id ) )
Täällä lataamme R:n 'dplyr'-paketin päästäksemme järjestämään arrange()-menetelmään. Sitten meillä on data.frame()-funktio, joka sisältää kaksi saraketta ja aseta DataFrame-muuttujaksi 'student'. Seuraavaksi otamme käyttöön arrange()-funktion 'dplyr'-paketista print()-funktiossa lajittelemaan annettu DataFrame. Arrange()-funktio ottaa 'opiskelija' DataFramen ensimmäisenä argumenttina, jonka jälkeen lajitellaan sarakkeiden 'Id'. Print()-funktio lopussa tulostaa lajitellun DataFrame-kehyksen konsoliin.
Näemme, mihin 'Id' -sarake on lajiteltu järjestyksessä seuraavassa tulosteessa:
Esimerkki 4: DataFrame:n lajittelu päivämäärän mukaan R:ssä
R:n DataFrame voidaan myös lajitella päivämääräarvojen mukaan. Tätä varten lajiteltu funktio on määritettävä as.date()-funktiolla päivämäärien muotoilemiseksi.
tapahtuma Päivämäärä = tiedot. kehys ( tapahtuma = c ( '4/3/2023' , '2/2/2023' ,'10.1.2023' , '29.3.2023' ) ,
maksuja = c ( 3100 , 2200 , 1000 , 2900 ) )
tapahtuma Päivämäärä [ Tilaus ( kuten . Päivämäärä ( event_date$event , muoto = '%d/%m/%Y' ) ) , ]
Täällä meillä on 'event_date' DataFrame, joka sisältää 'tapahtuma'-sarakkeen päivämäärämerkkijonoineen muodossa 'kuukausi/päivä/vuosi'. Meidän on lajiteltava nämä päivämäärämerkkijonot nousevaan järjestykseen. Käytämme order()-funktiota, joka lajittelee DataFramen tapahtumasarakkeen mukaan nousevaan järjestykseen. Suoritamme tämän muuntamalla 'tapahtuma'-sarakkeen päivämäärämerkkijonot todellisiksi päivämääriksi 'as.Date'-funktiolla ja määrittämällä päivämäärämerkkijonojen muodon 'format'-parametrilla.
Siten edustamme tietoja, jotka on lajiteltu 'tapahtuma'-päivämääräsarakkeen mukaan nousevassa järjestyksessä.

Esimerkki 5: DataFramen lajittelu Setorder()-menetelmällä R:ssä
Samoin setorder() on myös toinen tapa lajitella DataFrame. Se lajittelee DataFramen ottamalla argumentin aivan kuten arrange()-metodi. Setorder()-menetelmän R-koodi annetaan seuraavasti:
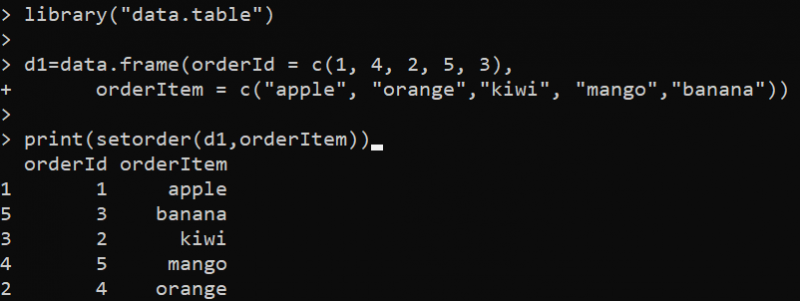
kirjasto ( 'data.taulukko' )d1 = tiedot. kehys ( tilausnumero = c ( 1 , 4 , 2 , 5 , 3 ) ,
tilata tuote = c ( 'omena' , 'oranssi' , 'kiivi' , 'mango' , 'banaani' ) )
Tulosta ( aseta järjestys ( d1 , tilata tuote ) )
Tässä asetamme ensin data.table-kirjaston, koska setorder() on tämän paketin funktio. Sitten käytämme data.frame()-funktiota DataFrame-kehyksen luomiseen. DataFrame on määritetty vain kahdella sarakkeella, joita käytämme lajitteluun. Tämän jälkeen asetamme setorder()-funktion print()-funktioon. Setorder()-funktio ottaa 'd1' DataFramen ensimmäisenä parametrina ja sarakkeen 'orderId' toiseksi parametriksi, jonka mukaan DataFrame lajitellaan. Funktio 'setorder' järjestää datataulukon rivit uudelleen nousevaan järjestykseen 'orderId'-sarakkeen arvojen perusteella.
Lajiteltu DataFrame on tulos R:n seuraavassa konsolissa:
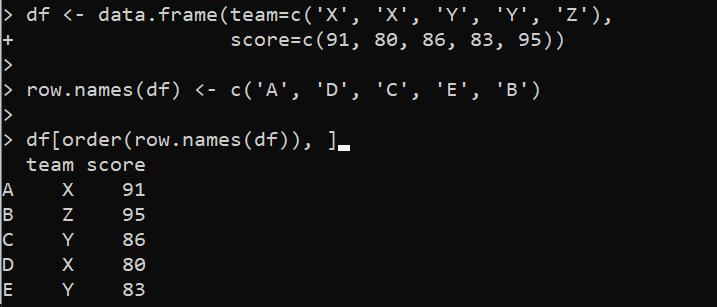
Esimerkki 6: DataFramen lajittelu käyttäen Row.Names()-menetelmää R:ssä
Metodi row.names() on myös tapa lajitella DataFrame R:ssä. row.names() lajittelee DataFrame-kehykset määritetyn rivin mukaan.
df < - tiedot. kehys ( tiimi = c ( 'X' , 'X' , 'JA' , 'JA' , 'KANSSA' ) ,pisteet = c ( 91 , 80 , 86 , 83 , 95 ) )
rivi. nimet ( df ) < - c ( 'A' , 'D' , 'C' , 'JA' , 'B' )
df [ Tilaus ( rivi. nimet ( df ) ) , ]
Tässä data.frame()-funktio on perustettu 'df'-muuttujaan, jossa sarakkeet määritetään arvoineen. Sitten DataFramen rivien nimet määritetään käyttämällä row.names()-funktiota. Tämän jälkeen kutsumme order()-funktiota lajittelemaan DataFrame rivinimien mukaan. Order()-funktio palauttaa lajiteltujen rivien indeksit, joita käytetään DataFramen rivien järjestämiseen.
Tulos näyttää järjestetyn DataFrame-kehyksen rivien mukaan aakkosjärjestyksessä:
Johtopäätös
Olemme nähneet erilaisia toimintoja DataFrame-kehysten lajitteluun R:ssä. Jokaisella menetelmällä on etu, ja ne tarvitsevat lajittelutoiminnon. DataFramen lajittelussa R-kielellä voi olla useampia menetelmiä tai tapoja, mutta order(), arrange() ja setorder() -menetelmät ovat tärkeimmät ja helpoimmat lajittelussa.