Tässä artikkelissa keskustelemme jakamisesta ERI muisti ' pytorch_cuda_alloc_conf ”menetelmä.
Mikä on 'pytorch_cuda_alloc_conf' -menetelmä PyTorchissa?
Pohjimmiltaan ' pytorch_cuda_alloc_conf ” on PyTorch-kehyksen ympäristömuuttuja. Tämä muuttuja mahdollistaa käytettävissä olevien prosessointiresurssien tehokkaan hallinnan, jolloin mallit toimivat ja tuottavat tuloksia mahdollisimman lyhyessä ajassa. Jos sitä ei tehdä kunnolla, ' ERI ' laskenta-alusta näyttää ' muisti loppu ”virhe ja vaikuttaa suoritusaikaan. Mallit, jotka on koulutettava suurille tietomäärille tai joilla on suuria ' eräkoot ' voi aiheuttaa ajonaikaisia virheitä, koska oletusasetukset eivät ehkä riitä niihin.
' pytorch_cuda_alloc_conf 'muuttuja käyttää seuraavaa' vaihtoehtoja ” käsittelemään resurssien allokointia:
- syntyperäinen : Tämä vaihtoehto käyttää PyTorchin jo käytettävissä olevia asetuksia varaamaan muistia käynnissä olevalle mallille.
- max_split_size_mb : Se varmistaa, että mitään määritettyä kokoa suurempia koodilohkoja ei jaeta. Tämä on tehokas keino estää ' pirstoutuminen ”. Käytämme tätä vaihtoehtoa tämän artikkelin esittelyyn.
- roundup_power2_divisions : Tämä vaihtoehto pyöristää varauksen koon lähimpään ' teho 2 ”-jako megatavuina (MB).
- roundup_bypass_threshold_mb: Se voi pyöristää allokoinnin koon jokaiselle pyynnölle, joka ylittää määritetyn kynnyksen.
- roskien_keräyksen_kynnys : Se estää latenssia käyttämällä GPU:n käytettävissä olevaa muistia reaaliajassa varmistaakseen, että Reclaim-all -protokollaa ei aloiteta.
Kuinka varata muistia 'pytorch_cuda_alloc_conf' -menetelmällä?
Mikä tahansa malli, jossa on suuri tietojoukko, vaatii lisämuistin varauksen, joka on suurempi kuin oletusarvoisesti asetettu. Mukautettu kohdistaminen on määritettävä ottaen huomioon mallivaatimukset ja käytettävissä olevat laitteistoresurssit.
Noudata alla annettuja ohjeita käyttääksesi ' pytorch_cuda_alloc_conf ” -menetelmä Google Colab IDE:ssä, jolla voit varata enemmän muistia monimutkaiselle koneoppimismallille:
Vaihe 1: Avaa Google Colab
Etsi Google Yhteistyö selaimessa ja luo ' Uusi muistikirja ”työn aloittamiseksi:
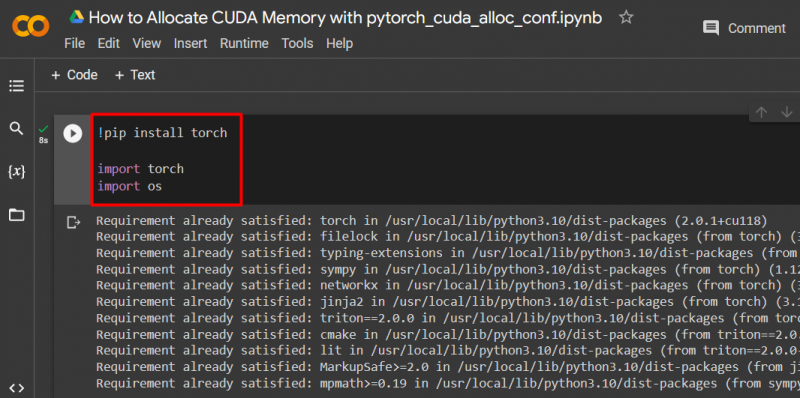
Vaihe 2: Mukautetun PyTorch-mallin määrittäminen
Asenna PyTorch-malli käyttämällä ' !pip ' asennuspaketti asentaaksesi ' taskulamppu 'kirjasto ja' tuonti 'komento tuoda' taskulamppu ' ja ' sinä ” kirjastot projektiin:
tuonti taskulamppu
tuo meille
Tätä projektia varten tarvitaan seuraavat kirjastot:
- Soihtu – Tämä on peruskirjasto, johon PyTorch perustuu.
- SINÄ – ' käyttöjärjestelmä '-kirjastoa käytetään käsittelemään ympäristömuuttujiin liittyviä tehtäviä, kuten ' pytorch_cuda_alloc_conf ” sekä järjestelmähakemisto ja tiedostooikeudet:
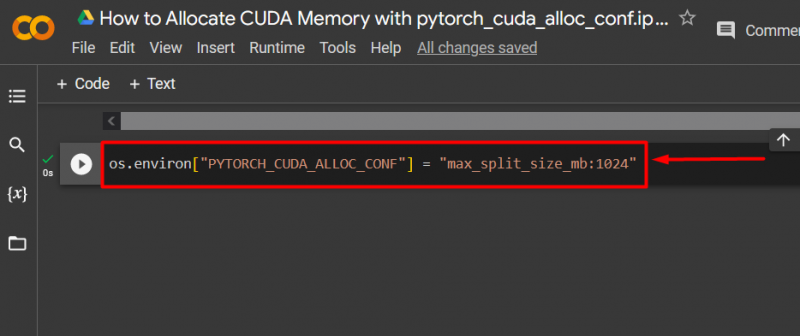
Vaihe 3: Varaa CUDA-muisti
Käytä ' pytorch_cuda_alloc_conf ' -menetelmä määrittääksesi enimmäisjaon koon käyttämällä ' max_split_size_mb ':
Vaihe 4: Jatka PyTorch-projektia
Kun olet määrittänyt ' ERI 'tilan jakaminen ' max_split_size_mb ' -vaihtoehto, jatka PyTorch-projektin parissa työskentelemistä normaalisti ilman pelkoa ' muisti loppu ”virhe.
Huomautus : Pääset käyttämään Google Colab -muistikirjaamme tästä linkki .
Pro-Tip
Kuten aiemmin mainittiin, ' pytorch_cuda_alloc_conf ” -menetelmässä voi olla mikä tahansa yllä olevista vaihtoehdoista. Käytä niitä syväoppimisprojektiesi erityisvaatimusten mukaisesti.
Menestys! Olemme juuri osoittaneet, kuinka käyttää ' pytorch_cuda_alloc_conf '-menetelmä määrittää ' max_split_size_mb ” PyTorch-projektille.
Johtopäätös
Käytä ' pytorch_cuda_alloc_conf ” -menetelmä CUDA-muistin varaamiseksi käyttämällä mitä tahansa sen käytettävissä olevista vaihtoehdoista mallin vaatimusten mukaisesti. Nämä vaihtoehdot on tarkoitettu helpottamaan tiettyä käsittelyongelmaa PyTorch-projekteissa paremman suoritusajan ja sujuvamman toiminnan takaamiseksi. Tässä artikkelissa olemme esitelleet syntaksin ' max_split_size_mb ” -vaihtoehto määrittääksesi jaon enimmäiskoon.