R:ssä sarakkeiden lukumäärän saaminen on perustoiminto, jota vaaditaan monissa tilanteissa käytettäessä DataFrame-kehystä. Kun alijoukkoa, analysoidaan, manipuloitaessa, julkaistaessa ja visualisoitaessa tietoja, sarakkeiden määrä on ratkaisevan tärkeä tietää. Siksi R tarjoaa erilaisia lähestymistapoja määritellyn DataFramen sarakkeiden kokonaismäärän saamiseksi. Tässä artikkelissa käsittelemme joitakin lähestymistapoja, jotka auttavat meitä saamaan DataFramen sarakkeiden lukumäärän.
Esimerkki 1: Ncol()-funktion käyttö
ncol() on yleisin funktio datakehysten sarakkeiden kokonaissumman saamiseksi.
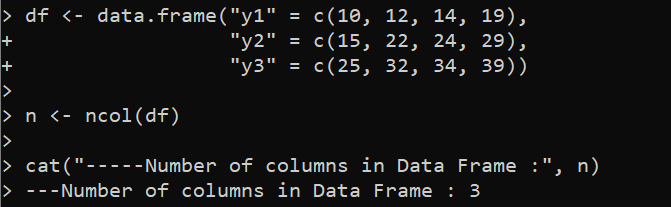
df <- data.frame('y1' = c(10, 12, 14, 19),
'y2' = c(15, 22, 24, 29),
'y3' = c(25, 32, 34, 39))
n <- ncol(df)
cat('-----Sarakkeiden lukumäärä tietokehyksessä :', n)
Tässä esimerkissä luomme ensin 'df' DataFrame -tietokehyksen, jossa on kolme saraketta, jotka on merkitty 'y1', 'y2' ja 'y3' käyttämällä data.frame()-funktiota R:ssä. Jokaisen sarakkeen elementit määritetään käyttämällä c()-funktio, joka luo elementtivektorin. Sitten ncol()-funktiota käytetään 'n'-muuttujan avulla määrittämään sarakkeiden kokonaismäärä 'df' DataFrame -kehyksessä. Lopuksi kuvailevan viestin ja 'n'-muuttujan kanssa toimitettu cat()-funktio tulostaa tulokset konsoliin.
Kuten odotettiin, haettu tulos osoittaa, että määritetyssä DataFrame-kehyksessä on kolme saraketta:
Esimerkki 2: Laske tyhjän datakehyksen sarakkeiden kokonaismäärä
Seuraavaksi käytämme ncol()-funktiota tyhjään DataFrame-kehykseen, joka saa myös sarakkeiden kokonaisarvot, mutta arvo on nolla.
tyhjä_df <- data.frame()n <- ncol(tyhjä_df)
cat('---Sarakkeet tietokehyksessä :', n)
Tässä esimerkissä luomme tyhjän DataFramen, 'empty_df', kutsumalla data.frame() määrittämättä sarakkeita tai rivejä. Seuraavaksi käytämme ncol()-funktiota, jota käytetään etsimään sarakkeiden lukumäärää DataFramesta. Funktio ncol() asetetaan 'empty_df' DataFrame:lla tässä saadakseen sarakkeiden kokonaismäärän. Koska 'empty_df' DataFrame on tyhjä, siinä ei ole sarakkeita. Joten ncol(empty_df) -funktion tulos on 0. Tulokset näytetään cat()-funktiolla, joka on otettu käyttöön tässä.
Tulos näyttää odotetusti arvon '0', koska DataFrame on tyhjä.

Esimerkki 3: Select_If()-funktion käyttö Length()-funktion kanssa
Jos haluamme noutaa minkä tahansa tyypin sarakkeiden lukumäärän, meidän tulee käyttää select_if()-funktiota yhdessä R:n pituus()-funktion kanssa. Näitä toimintoja käytetään, jotka yhdistetään kunkin tyypin sarakkeiden kokonaismäärän saamiseksi. . Koodi näiden toimintojen käyttämiseksi on toteutettu seuraavassa:
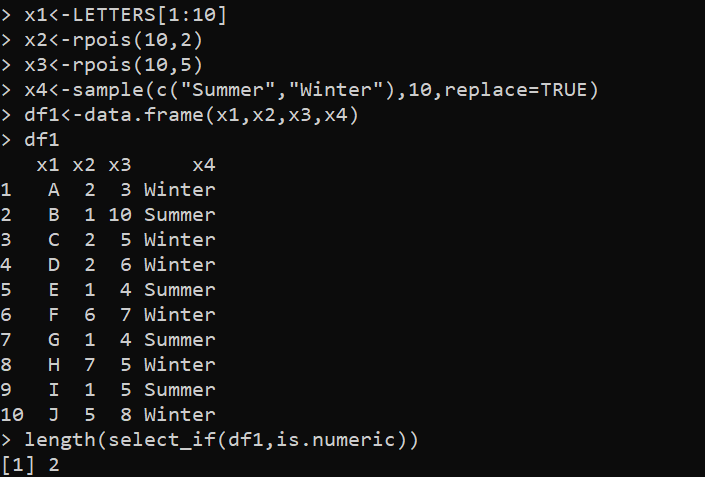
kirjasto (dplyr)x1<-LETTERS[1:10]
x2<-rpois(10,2)
x3<-rpois(10,5)
x4<-sample(c('Kesä','Talvi'),10,korvaa=TOSI)
df1<-data.frame(x1,x2,x3,x4)
df1
pituus(select_if(df1,is.numeric))
Tässä esimerkissä lataamme ensin dplyr-paketin, jotta voimme käyttää select_if()-funktiota ja pituus()-funktiota. Sitten luomme neljä muuttujaa - 'x1', 'x2', 'x3' ja 'x4'. Tässä 'x1' sisältää englannin aakkosten 10 ensimmäistä isoa kirjainta. Muuttujat 'x2' ja 'x3' luodaan käyttämällä rpois()-funktiota kahden erillisen 10 satunnaisluvun vektorin luomiseksi parametreilla 2 ja 5. 'x4'-muuttuja on tekijävektori, jossa on 10 elementtiä, jotka on otettu satunnaisesti vektorista c ('Kesä', 'Talvi').
Sitten yritämme luoda 'df1' DataFramen, jossa kaikki muuttujat välitetään data.frame()-funktiossa. Lopuksi kutsumme pituus()-funktion määrittääksemme 'df1'-tietokehyksen pituuden, joka luodaan käyttämällä dplyr-paketin select_if()-funktiota. Select_if()-funktio valitsee sarakkeet 'df1'-tietokehyksestä argumentiksi ja is.numeric()-funktio valitsee vain sarakkeet, jotka sisältävät numeerisia arvoja. Sitten pituus()-funktio saa sarakkeiden kokonaismäärän, joka valitaan komennolla select_if(), joka on koko koodin tulos.
Sarakkeen pituus näkyy seuraavassa tulosteessa, joka ilmaisee DataFramen sarakkeiden kokonaismäärän:
Esimerkki 4: Sapply()-funktion käyttäminen
Toisaalta, jos haluamme vain laskea sarakkeiden puuttuvat arvot, meillä on sapply()-funktio. Sapply()-funktio iteroi jokaisen DataFramen sarakkeen yli toimiakseen erityisesti. Sapply()-funktio välitetään ensin DataFrame-argumentin kanssa. Sitten toiminto suoritetaan kyseiselle DataFrame-kehykselle. Sapply()-funktion toteutus NA-arvojen määrän saamiseksi DataFrame-sarakkeissa on seuraava:
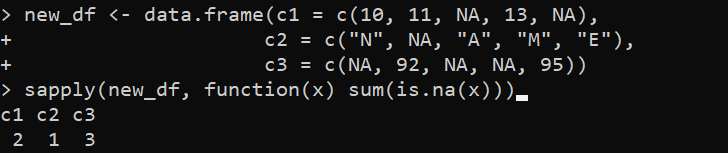
new_df <- data.frame(c1 = c(10, 11, NA, 13, NA),c2 = c('N', NA, 'A', 'M', 'E'),
c3 = c(NA, 92, NA, NA, 95))
sapply(new_df, function(x) summa(is.na(x)))
Tässä esimerkissä luomme 'new_df' DataFramen kolmella sarakkeella - 'c1', 'c2' ja 'c3'. Ensimmäiset sarakkeet 'c1' ja 'c3' sisältävät numeeriset arvot, mukaan lukien joitain puuttuvia arvoja, joita edustaa NA. Toinen sarake, 'c2', sisältää merkit, mukaan lukien joitakin puuttuvia arvoja, joita myös edustaa NA. Sitten käytämme sapply()-funktiota 'new_df' DataFrame -kehykseen ja laskemme puuttuvien arvojen lukumäärän kussakin sarakkeessa käyttämällä sum()-lauseketta sapply()-funktion sisällä.
Is.na()-funktio on lauseke, joka on määritetty sum()-funktiolle, joka palauttaa loogisen vektorin, joka osoittaa, puuttuuko jokainen sarakkeen elementti vai ei. Sum()-funktio laskee kussakin sarakkeessa puuttuvien arvojen lukumäärän yhteen TRUE-arvot.
Tästä syystä tulos näyttää kokonaisNA-arvot kussakin sarakkeessa:
Esimerkki 5: Dim()-funktion käyttö
Lisäksi haluamme saada sarakkeiden kokonaismäärän yhdessä DataFramen rivien kanssa. Sitten dim()-funktio antaa DataFramen mitat. Dim()-funktio ottaa objektin argumentiksi, jonka mitat halutaan hakea. Tässä on koodi dim()-funktion käyttämiseen:
d1 <- data.frame(tiimi=c('t1', 't2', 't3', 't4'),pisteet=c(8, 10, 7, 4))
himmeä (d1)
Tässä esimerkissä määritetään ensin 'd1' DataFrame, joka luodaan data.frame()-funktiolla, jossa kaksi saraketta asetetaan 'tiimi' ja 'pisteet'. Tämän jälkeen kutsumme dim()-funktion 'd1' DataFramen yli. Dim()-funktio palauttaa DataFramen rivien ja sarakkeiden määrän. Siksi, kun suoritamme dim(d1), se palauttaa vektorin, jossa on kaksi elementtiä – joista ensimmäinen heijastaa rivien lukumäärää 'd1' DataFramessa ja joista toinen edustaa sarakkeiden määrää.
Tulos edustaa DataFramen mittoja, jossa arvo '4' osoittaa sarakkeiden kokonaismäärän ja arvo '2' edustaa rivejä:

Johtopäätös
Olemme nyt oppineet, että R:n sarakkeiden lukumäärän laskeminen on yksinkertainen ja tärkeä toimenpide, joka voidaan suorittaa DataFrame-kehyksessä. Kaikista funktioista ncol()-funktio on kätevin tapa. Nyt tunnemme eri tavat saada sarakkeiden määrä annetusta DataFramesta.