Tämä artikkeli keskittyy suodatinlausekkeisiin. Siksi määrittelemme suodatinlausekkeet, selitämme, miksi ja milloin ne ovat sovellettavissa, ja annamme vaiheittaisen oppaan niiden käyttämiseen sopivien esimerkkien kautta.
Mitä ovat suodatinlausekkeet?
Suodatuslausekkeet ovat suosittu tekniikka DynamoDB:n tietojen suodattamiseksi kysely- ja tarkistustoimintojen aikana. DynamoDB:ssä oikea tietojen mallinnus ja organisointi perustuvat suodatukseen. Vaikka useimmissa sovelluksissa on aina tonneittain tallennettuja tietoja, saatat tarvita kiireellisesti jonkin kohteen valtavasta sotkusta.
Kykysi noutaa oikeat tiedot aina kun tarvitset niitä riippuu tietokantasi suodatusominaisuuksista, ja tässä on apua suodatinlausekkeista. Ne määrittävät kyselyn tulokset, jotka haluat palauttaa sinulle, koska he hylkäävät loput kohteet.
Voit käyttää palvelinpuolen suodattimien suodatinlausekkeita nimikkeiden määritteissä sen jälkeen, kun kyselytoiminto on valmis, mutta ennen kuin palvelin palauttaa kyselykutsusi tulokset. Tämä tarkoittaa, että kyselysi kuluttaa edelleen saman määrän lukukapasiteettia riippumatta siitä, käytätkö suodatinlauseketta.
Lisäksi, kuten tavalliset kyselytoiminnot, 1 Mt:n tietoraja kyselytoimintoille tapahtuu ennen suodatinlauseketoiminnon arviointia. Tämän toiminnon avulla voit vähentää hyötykuormaa, etsiä tiettyjä kohteita ja parantaa yksinkertaisuutta ja luettavuutta sovelluskehityksen aikana.
Suodatinlausekkeen syntaksi ja esimerkit
Erityisesti sekä suodatinlausekkeet että avainlausekkeet käyttävät samaa syntaksia. Lisäksi suodatinlausekkeet ja ehtolausekkeet voivat käyttää samoja funktioita, vertailijoita ja loogisia operaattoreita.
Muita lausekkeita suodattavia operaattoreita ovat myös CONTAINS-, TAI-, not-equals ()-operaattori, IN-operaattori, BETWEEN-operaattori, BEGINS_WITH-operaattori, SIZE-operaattori ja EXISTS-operaattori.
Esimerkki 1: Kysely AWS CLI:n ja DynamoDB:n ensisijaisten avainten avulla
Tämä esimerkki hakee Musiikki-taulukosta tiettyä genreä (osioavain) ja tiettyä esittäjää (lajitteluavain). Apuohjelma palauttaa tuloksen vain niille kohteille, jotka vastaavat tiettyä osioavainta ja lajitteluavainta eniten katselukertoja saaville kappaleille.
Voit määrittää näkymien määrän (#v) komennossa. Merkitsemme esimerkiksi vähimmäisrajamme 1 000 katselukertaa, mikä tarkoittaa, että vain yli 1000 katselukertaa saaneiden kappaleiden tulokset tulevat takaisin.
$ aws dynamodb kysely \--taulukon nimi Musiikki \
--avain-ehto-lauseke 'Genre = :fn ja Artist = :sub' \
--filter-lauseke '#v >= :num(1000)' \
--lauseke-attribuuttien nimet '{'#v': 'Näkymät'} \
--lauseke-attribuutti-arvot tiedosto: // Values.json
Esimerkki 2: AWS CLI:n käyttö ehtolausekkeen kanssa
Voimme järjestää saman kyselyn uudelleen kuin edellisessä esimerkissä, mutta nyt ehtoavaimet suodattimiemme rinnalla. Se ei sisällä lajitteluavainta. Sen sijaan se hakee kaikki tietyn esittäjän tietueet, joilla on yli 1 000 näyttökertaa. Se voidaan myös rekonstruoida antamaan tilauksia, jotka ylittävät tietyn numeron tietylle käyttäjätunnukselle (asiakastunnus).
$ aws dynamodb kysely \--taulukon nimi Musiikki \
--avain-ehto-lauseke 'Käyttäjänimi = :käyttäjänimi' \
--filter-lauseke 'Summa > :summa' \
--lauseke-attribuutti-arvot '{
':käyttäjänimi': { 'S': 'artisti' },
':summa': { 'N': '1000' }
}' \
$LOCAL
Esimerkki tuloksesta näyttää tältä:
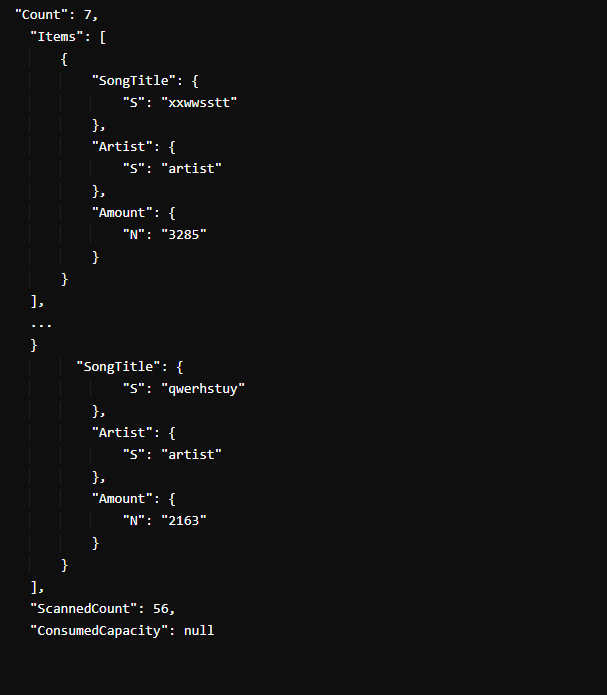
Annettu kuva osoittaa, että saman artistin 56 kappaleen nimestä vain seitsemällä kappaleella on yli 1 000 katselukertaa. Olemme kuitenkin lyhentäneet lukua lyhennyksen vuoksi ja sisällyttäneet luetteloon vain ensimmäisen ja viimeisen tuloksen.
Esimerkki 3: Suodatinlausekkeiden käyttö No-Equal () -operaattorin kanssa
Seuraavassa Java-apuohjelmassa haluamme tehdä kyselyn taulukostamme (Movie Collection) kaikille elokuville, jotka eivät ole yhtä kuin 'Movie X'. Varmista, että käytät suodatinlauseketta, jossa on attribuutti (#nimi) lausekkeen attribuutin arvon (:nimi) rinnalla, kuten seuraavassa kuvataan:
const AWS = vaadi ( 'aws-sdk' ) ;AWS.config.update ( { alue: 'eu-länsi-1' } ) ;
const dynamodb = uusi AWS.DynamoDB.DocumentClient ( ) ;
var params = {
Taulukon nimi: 'elokuvakokoelma' ,
KeyConditionExpression: '#PK = :PK' ,
Suodatinlauseke: '#nimi :nimi' , ( suodatinlauseke )
ExpressionAttributeNames: { '#PK' : 'PK' , '#nimi' : 'nimi' } , ( ehdon ilmaisu )
ExpressionAttributeValues: {
':PK' : 'OgejhHrdRS453HGD4Ht44' ,
':nimi' : 'Elokuva X'
}
} ;
dynamodb.query ( parametrit, toiminto ( virhe, data ) {
jos ( err ) console.log ( err ) ;
muu console.log ( tiedot ) ;
} ) ;
Esimerkki 4: Suodatinlausekkeiden käyttäminen skannausoperaattorin kanssa
Vaikka edellinen komento käyttää <>-komentoa hakemaan vain ne kohteet, jotka eivät vastaa elokuvan nimeä nimeltä Movie X, varmista, että käytät tässä avainehtolausekkeita yhdessä suodatinlausekkeen kanssa. Tämä johtuu siitä, että on mahdotonta suodattaa tietoja Query-operaattorissa ilman avainehtolauseketta.
var params = {Taulukon nimi: 'elokuvakokoelma' ,
Suodatinlauseke: 'PK = :PK ja #nimi :nimi' ,
ExpressionAttributeNames: { '#nimi' : 'nimi' } ,
ExpressionAttributeValues: {
':PK' : 'OgejhHrdRS453HGD4Ht44' ,
':nimi' : 'Elokuva X'
}
} ;
dynamodb.scan ( parametrit, toiminto ( virhe, data ) {
jos ( err ) console.log ( err ) ;
muu console.log ( tiedot ) ;
} ) ;
Johtopäätös
Tähän päättyy DynamoDB-opetusohjelmamme suodatinlausekkeista. Voit käyttää suodatinlausekkeita hakeaksesi joukon haluttuja tietoja, suodattaaksesi haetut tiedot tarkistuksen tai kyselyn jälkeen tai palauttaaksesi tietojoukon asiakkaalle. Vaikka sitä voidaan käyttää useiden työkalujen kanssa, on tapauksia, joissa suodatinlausekkeiden käyttö ei ole kannattavaa. Voit esimerkiksi käyttää niitä vain, jos sinulla on oikea tietomalli, kun käytät ensisijaista avainta ja poimit suuria osia tiedoista.