Pandat täyttävät NaN-arvot
Jos tietokehyksesi sarakkeessa on NaN- tai None-arvoja, voit käyttää 'fillna()'- tai 'replace()'-funktioita täyttääksesi ne nollalla (0).
täyttää()
NA/NaN-arvot täytetään tarjotulla lähestymistavalla käyttämällä “fillna()”-funktiota. Sitä voidaan käyttää ottamalla huomioon seuraava syntaksi:
Jos haluat täyttää yhden sarakkeen NaN-arvot, syntaksi on seuraava:

Kun sinun on täytettävä NaN-arvot koko DataFramelle, syntaksi on annettu:

Korvata()
Jos haluat korvata yhden NaN-arvojen sarakkeen, toimitettu syntaksi on seuraava:

Sen sijaan koko DataFramen NaN-arvojen korvaamiseksi meidän on käytettävä seuraavaa mainittua syntaksia:

Tässä kirjoituksessa tutkimme nyt ja opimme näiden molempien menetelmien käytännön toteutusta Pandas DataFrame -kehyksen NaN-arvojen täyttämiseksi.
Esimerkki 1: Täytä NaN-arvot Pandas “Fillna()” -menetelmällä
Tämä kuva havainnollistaa Pandasin 'DataFrame.fillna()' -funktion soveltamista NaN-arvojen täyttämiseen annetussa DataFramessa nollalla. Voit joko täyttää puuttuvat arvot yhteen sarakkeeseen tai täyttää ne koko DataFrame-kehykselle. Täällä näemme molemmat tekniikat.
Näiden strategioiden toteuttamiseksi meidän on saatava asianmukainen alusta ohjelman toteuttamiselle. Joten päätimme käyttää 'Spyder' -työkalua. Aloitimme Python-koodimme tuomalla 'pandas'-työkalupaketin ohjelmaan, koska meidän on käytettävä Pandas-ominaisuutta DataFrame-kehyksen rakentamiseen sekä sen puuttuvien arvojen täyttämiseen. Pd:tä käytetään 'pandan' aliaksena koko ohjelman ajan.
Nyt meillä on pääsy Panda-ominaisuuksiin. Käytämme ensin sen 'pd.DataFrame()'-funktiota DataFrame-kehyksen luomiseen. Käytimme tätä menetelmää ja alustimme sen kolmella sarakkeella. Näiden sarakkeiden otsikot ovat 'M1', 'M2' ja 'M3'. M1-sarakkeen arvot ovat '1', 'Ei mitään', '5', '9' ja '3'. 'M2':n merkinnät ovat 'Ei mitään', '3', '8', '4' ja '6'. Kun 'M3' tallentaa tiedot muodossa '1', '2', '3', '5' ja 'ei mitään'. Tarvitsemme DataFrame-objektin, johon voimme tallentaa tämän DataFramen, kun 'pd.DataFrame()'-menetelmää kutsutaan. Loimme 'puuttuvan' DataFrame-objektin ja määritimme sen tuloksen perusteella, jonka saimme 'pd.DataFrame()'-funktiosta. Sitten käytimme Pythonin 'print()' -menetelmää DataFramen näyttämiseen Python-konsolissa.
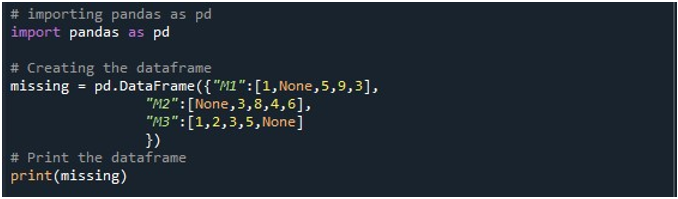
Kun suoritamme tämän koodinpätkän, kolmen sarakkeen DataFrame voidaan tarkastella päätteessä. Tässä voimme havaita, että kaikki kolme saraketta sisältävät nolla-arvot.
Loimme DataFramen, jossa on nolla-arvoja, jotta Pandasin “fillna()”-funktio täyttää puuttuvat arvot nollalla. Opitaanpa, kuinka voimme tehdä sen.
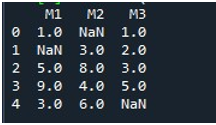
DataFramen näyttämisen jälkeen käynnistimme Pandasin 'fillna()' -toiminnon. Täällä opimme täyttämään puuttuvat arvot yhdessä sarakkeessa. Tämän syntaksi mainitaan jo opetusohjelman alussa. Annoimme DataFramen nimen ja määritimme tietyn sarakkeen otsikon '.fillna()'-funktiolla. Tämän menetelmän sulkeiden väliin annoimme arvon, joka laitetaan nollapaikkoihin. DataFrame-nimi on 'puuttuu' ja tässä valitsemamme sarake on 'M2'. 'fillna()':n aaltosulkeiden välissä oleva arvo on '0'. Lopuksi kutsuimme 'print()'-funktiota tarkastellaksesi päivitettyä DataFramea.

Tässä näet, että DataFramen M2-sarakkeessa ei ole nyt puuttuvia arvoja, koska NaN-arvo on täytetty 0:lla.
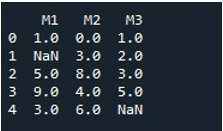
Koko DataFramen NaN-arvojen täyttämiseksi samalla menetelmällä kutsuimme 'fillna()'. Tämä on melko yksinkertaista. Annoimme DataFrame-nimen 'fillna()'-funktion kanssa ja määritimme funktion arvon '0' sulkeiden väliin. Lopuksi 'print()' -toiminto näytti meille täytetyn DataFramen.

Näin saamme DataFrame-kehyksen, jossa ei ole NaN-arvoja, koska kaikki arvot täytetään nyt nollalla.
Esimerkki 2: Täytä NaN-arvot Pandas “Replace()” -menetelmällä
Tämä artikkelin osa esittelee toisen menetelmän NaN-arvojen täyttämiseksi DataFrame-kehyksessä. Käytämme Pandasin 'replace()'-funktiota arvojen täyttämiseen yhdessä sarakkeessa ja täydellisessä DataFrame-kehyksessä.
Aloitamme koodin kirjoittamisen 'Spyder' -työkalussa. Ensin toimme tarvittavat kirjastot. Täällä latasimme Pandas-kirjaston, jotta Python-ohjelma voi käyttää Pandas-menetelmiä. Toinen lataamamme kirjasto on NumPy ja alias se 'np'. NumPy käsittelee puuttuvat tiedot 'replace()'-menetelmällä.
Sitten loimme DataFramen, jossa oli kolme saraketta - 'ruuvi', 'naula' ja 'pora'. Jokaisen sarakkeen arvot on annettu vastaavasti. 'Ruuvi'-sarakkeessa on arvot '112', '234', 'Ei mitään' ja '650'. 'Nail'-sarakkeessa on '123', '145', 'Ei mitään' ja '711'. Lopuksi 'drill' -sarakkeessa on arvot '312', 'Ei mitään', '500' ja 'Ei mitään'. DataFrame tallennetaan 'tool' DataFrame -objektiin ja näytetään 'print()'-menetelmällä.
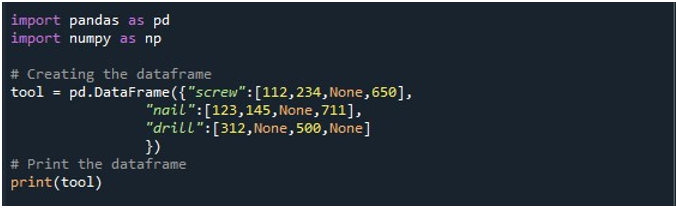
DataFrame, jossa on neljä NaN-arvoa tietueessa, näkyy seuraavassa tuloskuvassa:
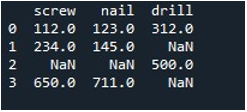
Nyt käytämme Pandasin 'replace()' -menetelmää täyttämään nolla-arvot yhdessä DataFrame-sarakkeessa. Tehtävää varten kutsuimme 'replace()'-funktion. Toimitimme DataFrame-nimen 'työkalu' ja sarakkeen 'ruuvi' menetelmällä '.replace()'. Asetamme sen aaltosulkeiden väliin arvon '0' DataFramen 'np.nan'-merkinnöille. Tulosteen näyttämiseen käytetään 'print()'-menetelmää.

Tuloksena oleva DataFrame näyttää meille ensimmäisen sarakkeen, jossa NaN-merkinnät on korvattu 0:lla 'ruuvi'-sarakkeessa.
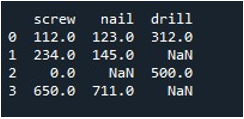
Nyt opimme täyttämään arvot koko DataFramessa. Kutsuimme 'replace()'-menetelmää DataFramen nimellä ja annoimme arvon, jonka haluamme korvata np.nan-merkinnöillä. Lopuksi tulostimme päivitetyn DataFramen 'print()'-funktiolla.

Tämä antaa meille tuloksena olevan DataFramen ilman puuttuvia tietueita.
Johtopäätös
DataFrame-kehyksen puuttuvien merkintöjen käsitteleminen on perustavanlaatuinen ja välttämätön vaatimus monimutkaisuuden vähentämiseksi ja tietojen uhmakkaaksi käsittelemiseksi data-analyysiprosessissa. Pandas tarjoaa meille muutamia vaihtoehtoja tämän ongelman ratkaisemiseksi. Olemme tuoneet tähän oppaaseen kaksi kätevää strategiaa. Toteutamme molemmat tekniikat käytännössä 'Spyder'-työkalun avulla suorittaaksemme mallikoodit, jotta asiat olisivat sinulle hieman ymmärrettäviä ja helpompia. Näiden toimintojen tuntemuksen saaminen terävöittää Panda-taitojasi.