Pandas Set_Option -menetelmä
Tänään tarkastelemme, kuinka 'pd.set_option()'-funktiota käytetään näyttämään kaikki Pandas-tietokehyksen sarakkeet, kun esität sen Spyder-työkalussasi. Käyttääksemme 'pd.set_option()' -toimintoa noudatamme annettua syntaksia:

Aloitetaan konseptin oppiminen Python-ohjelman käytännön toteutuksen avulla.
Esimerkki: Pandas Set_Option -menetelmän käyttäminen kaikkien sarakkeiden näyttämiseen
Tämä esittely on opas kaikkien DataFramen sarakkeiden näyttämiseen käyttämällä Pandasin 'set_option()' -toimintoa. Teemme selväksi tämän Python-menetelmän toteuttamisen jokaisen vaiheen yksityiskohdat.
Ensimmäinen vaatimus Python-skriptin käytännön toteutuksessa on löytää paras työkalu, jossa suoritat ohjelman. Työkalu, jota käytimme kuvassamme, on 'Spyder' -työkalu. Käynnistimme työkalun ja aloimme työskennellä Python-skriptin parissa.
Koodista alkaen meidän on aluksi tuotava tässä ohjelmassa tarvitsemamme edellytyskirjastot. Ensimmäinen Python-tiedostoomme ladattu kirjasto on Pandas-kirjasto, koska Pandas tarjoaa tässä käyttämämme toiminnot. Nimesimme tämän kirjaston nimellä 'pd'. Toinen lataamamme kirjasto on NumPy-kirjasto. NumPy (Numerical Python) on Python-ohjelmoinnin avulla kehitetty numeerinen laskentapaketti. Koodin Import NumPy -osio ohjaa Pythonin integroimaan NumPy-moduulin nykyiseen Python-tiedostoosi. Skriptin 'as np' -osa kehottaa sitten Pythonia määrittämään NumPylle 'np'-lyhenteen. Sen avulla voit käyttää NumPy-menetelmiä kirjoittamalla 'np.function_name' NumPy:n sijaan.
Aloitamme nyt pääkoodilla. Ohjelmamme tärkein ja perustarve on Pandas DataFrame. Joten näytämme kaikki sen sisältämät sarakkeet. Nyt on täysin sinun päätettävissäsi, haluatko luoda DataFramen tietyillä arvoilla vai haluatko tuoda CSV-tiedoston. Valitsimme tässä tapauksessa DataFramen luomisen NaN-arvoilla. Käytimme 'pd.DataFrame()' -menetelmää DataFrame-kehyksen muodostamiseksi. Tässä toimitimme kaksi parametria - 'indeksi' ja 'sarakkeet'. 'Indeksi'-argumentti viittaa riveihin, mikä tarkoittaa, että asetamme rivit DataFramelle.
Määritimme parametrin 'index' ja NumPy-funktion 'np.arange() arvolla '6'. Se luo kuusi riviä DataFrame-kehykselle. Se täyttää kaikki merkinnät NaN-arvoilla, koska emme ole antaneet sille mitään arvoa. Sarakkeet-argumenttia käytetään nimen mukaisesti asettamaan sarakkeet DataFramelle. Sille on myös määritetty 'np.arange()'-funktio, jonka sarakkeiden arvo on '25'. Siten se rakentaa 25 saraketta DataFrame-kehykselle.
Näin ollen, kun kutsumme 'pd.DataFrame()'-funktiota, meillä on DataFrame, jossa on 25 saraketta ja 6 riviä, jotka on täytetty nolla-arvoilla. Jotta tämä DataFrame voidaan säilyttää, meidän on rakennettava DataFrame-objekti, joka tallentaa sen sisällön. Siksi loimme DataFrame-objektin 'random' ja määritimme sille tuloksen, jonka saamme 'pd.DataFrame()'-metodista. Nyt haluat varmasti nähdä DataFramen luomisen. Python tarjoaa meille menetelmän tarkastella tulostetta näytöllä, joka on 'print()'-funktio. Käytimme tätä menetelmää välittämällä DataFrame-objektin 'random' sen parametriksi.
Kun suoritamme tämän koodinpätkän, saamme DataFrame-kehyksemme NaN-arvoilla, jotka näkyvät päätteessä. Tässä voimme havaita, että osa ensimmäisistä sarakkeista ja vain muutama lopusta ovat näkyvissä. Kaikki välissä olevat sarakkeet on katkaistu. Oletusarvoisesti se piilottaa osan riveistä ja sarakkeista, jotta se ei aiheuta turhautumista käyttäjälle näyttämällä valtavia tietojoukkoja.
Voit jopa tarkistaa DataFramen sarakkeiden kokonaismäärän käyttämällä Pandasin len()-toimintoa. Kirjoita 'len()'-funktio 'Spyder'-työkalusi konsoliin. Kirjoita DataFramen nimi sen sulkeisiin '.columns'-ominaisuuden avulla. Se palauttaa meille DataFrame-kehyksesi sarakkeiden kokonaispituuden.

Se palauttaa DataFrame-kehyksemme pituuden, joka on 25.
Nyt seuraava ja ydintehtävä on muuttaa oletusasetusta tulosteen näyttämiseksi. Joissakin tilanteissa haluat tarkastella koko DataFramea päätteessä. Oletusarvojen vuoksi monet merkinnät katkaistaan, mikä aiheuttaa käyttäjälle pettymyksen. Täällä opit ratkaisemaan tämän ongelman. Pandas tarjoaa meille 'pd.set_option()' -toiminnon näytön oletusasetusten muuttamiseksi. Heti DataFramen näyttämisen jälkeen konsolissa kutsumme 'pd.set_option()' -menetelmän. Määritämme tämän funktion sulkeissa olevan parametrin, jota meidän on käytettävä kaikkien DataFramen sarakkeiden näyttämiseen.
Tässä käytimme 'display.max_columns' näyttämään enimmäissarakkeet DataFramessa. Voimme myös määrittää tälle parametrille arvon, eli sarakkeiden enimmäismäärän, jotka haluat näyttää. Toisaalta määritimme 'display.max_columns' arvoksi 'Ei mitään', joka näyttää kaikki DataFramen sarakkeet enimmäispituuksilla. Lopuksi käytimme 'print()' -toimintoa näyttääksemme tuloksena olevan DataFramen, jossa kaikki sarakkeet näkyvät päätteessä.
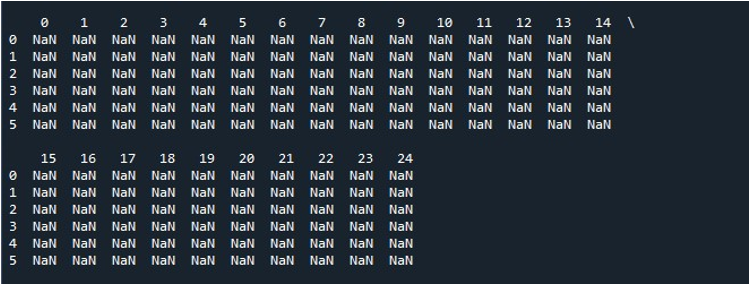
Kun painamme 'Suorita tiedosto' -vaihtoehtoa 'Spyder' -työkalussa, voimme tarkastella näytteillä olevaa DataFramea. Tässä DataFrame-kehyksessä on kuusi riviä ja sen sisältämien sarakkeiden määrä on 25. Yksikään sarake ei ole katkaistu, koska 'pd.set_option()'-funktio, jolla on sarakkeen enimmäispituus, on nyt käytössä.
Voimme jopa nollata näyttövaihtoehdon, koska kun asetamme näytön pituuden maksimiin, se jatkaa DataFrame-kehysten näyttämistä kaikkien kyseisen Python-tiedoston sarakkeiden kanssa. Tätä varten käytämme Pandasta 'pd.reset_option()'. Kutsumme tämän funktion ja tarjoamme 'display.max_columns' tämän funktion parametriksi.

Näin saamme toimitetun DataFramen alkuperäiset näyttöasetukset.
Johtopäätös
Täydellisen tulosteen tarkasteleminen päätelaitteessa valtavan tietojoukon kanssa saa meidät joskus vaikeuksiin, kun työkalun oletusasetukset ovat ristiriidassa käyttäjän tarpeiden kanssa. Tämän takaiskun ratkaisemiseksi Pandas antaa meille menetelmän 'pd.set_option()'. Tässä oppimisoppaassa esittelimme sinulle tämän menetelmän ja tarpeen käyttää sitä. Esitimme aiheen käytännössä käännetyillä ja suoritetuilla Python-näytekoodeilla. Toistimme 'Spyderillä' tehdyn kuvituksen tulokset. Selitimme, kuinka kaikki DataFramen sarakkeet näytetään konsolissa muuttamalla oletusasetuksia sekä palauttamalla kaikki asetukset alkuperäisiksi. Täysin keskittyneen huomion kiinnittäminen moduulin käytännön toteutukseen mahdollistaa sen hyödyntämisen aina, kun kohtaat tällaisia ongelmia.