'CSV (Comma-Separated Values) on yksi monipuolisimmista ja helpoimmista tietomuodoista. Se on kevyt tietomuoto, jonka avulla kehittäjät ja sovellukset voivat siirtää ja jäsentää tietoja lähteestä toiseen.
CSV-data tallentaa tiedot taulukkomuodossa, jossa jokainen sarake on erotettu pilkulla ja uusi tietue varataan uudelle riville. Tämä tekee siitä erittäin hyvän valinnan tietokantojen, kuten SQL-tietokantojen, Cassandra-tietojen ja muiden vientiin.
Siksi ei ole yllätys, että kohtaat skenaarion, jossa sinun on tuotava CSV-tiedosto tietokantaasi.
Tämän opetusohjelman tavoitteena on näyttää sinulle nopea ja yksinkertainen tapa tuoda CSV-tiedosto Elasticsearch-klusteriisi Kibana-hallintapaneelin avulla.
Hyppäämme sisään.
Vaatimukset
Varmista ennen sukellusta, että sinulla on seuraavat vaatimukset:
- Elasticsearch-klusteri, jonka terveydentila on vihreä.
- Kibana-palvelin yhdistetty Elasticsearch-klusteriisi.
- Riittävät käyttöoikeudet klusterin indeksien hallintaan.
Esimerkki CSV-tiedostosta
Kuten tavallista, ensimmäinen vaatimus on lähde-CSV-tiedosto. On hyvä varmistaa, että CSV-tiedostosi tiedot ovat hyvin muotoiltuja ja ettei niissä ole virheitä.
Käytämme esimerkkinä ilmaista tietojoukkoa, joka sisältää Amazon Primen elokuvia ja TV-ohjelmia.
Avaa selaimesi ja siirry alla olevaan resurssiin:
https://www.kaggle.com/datasets/shivamb/amazon-prime-movies-and-tv-shows
Noudata ohjeita ladataksesi tietojoukon paikalliselle koneellesi. Voit purkaa ladatun arkiston komennolla:
$ pura vetoketju a~ / Lataukset / arkisto.zip
Tuo CSV-tiedosto
Kun lähdetiedostosi on valmis, voimme jatkaa ja keskustella sen tuomisesta.
Aloita siirtymällä Kibana-kotipaneeliin ja valitsemalla 'lähetä tiedosto'.
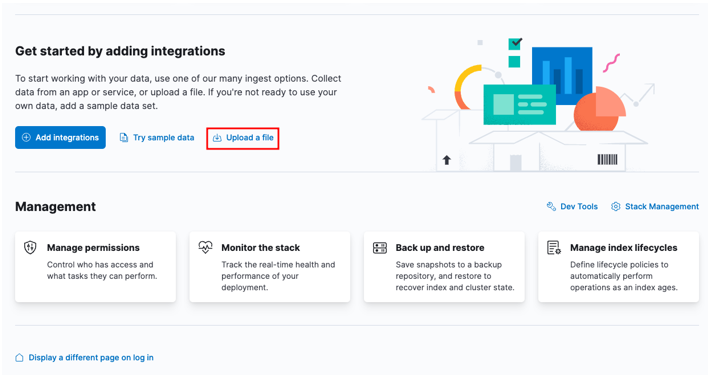
Etsi käynnistysikkunasta kohde-CSV-tiedosto, jonka haluat tuoda.
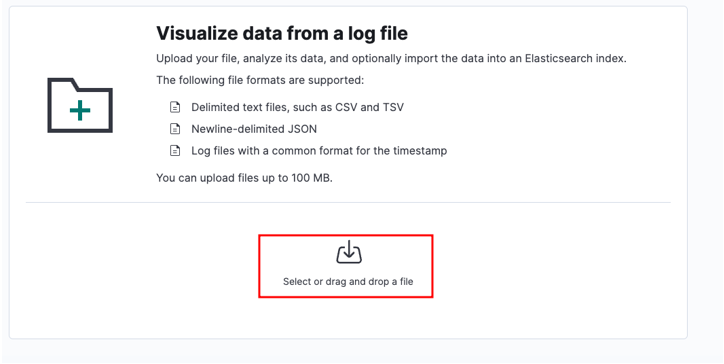
Valitse lähdetiedosto ja napsauta Lataa.
Anna Elasticsearchin ja Kibanan analysoida ladattua tiedostoa. Tämä jäsentää CSV-tiedoston ja määrittää tietomuodon, kentät, tietotyypit jne.
HUOMAUTUS: Tämä prosessi voi kestää jonkin aikaa klusterin kokoonpanosta ja tietojen koosta riippuen. Varmista, että pääsolmu vastaa aikakatkaisujen välttämiseksi.
Kun prosessi on valmis, sinun pitäisi saada näyte tiedostosi sisällöstä ja Elasticin analysoimat tiedostotilastot.
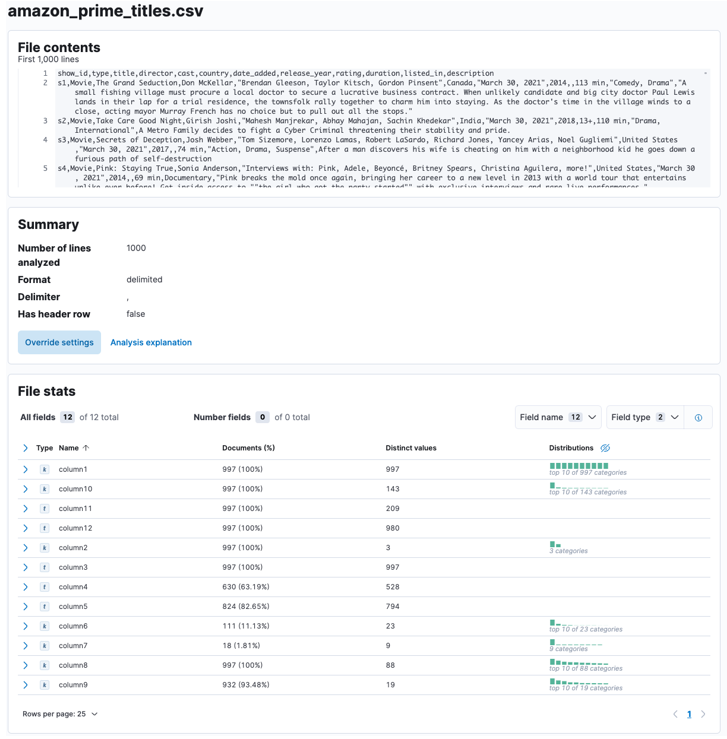
Voit räätälöidä useita parametreja, esimerkiksi erottimen, otsikkorivit jne. Voimme esimerkiksi mukauttaa yllä olevaa tulostetta kertomaan Elasticille, että CSV-tiedostomme sisältää otsikkotiedostoja.
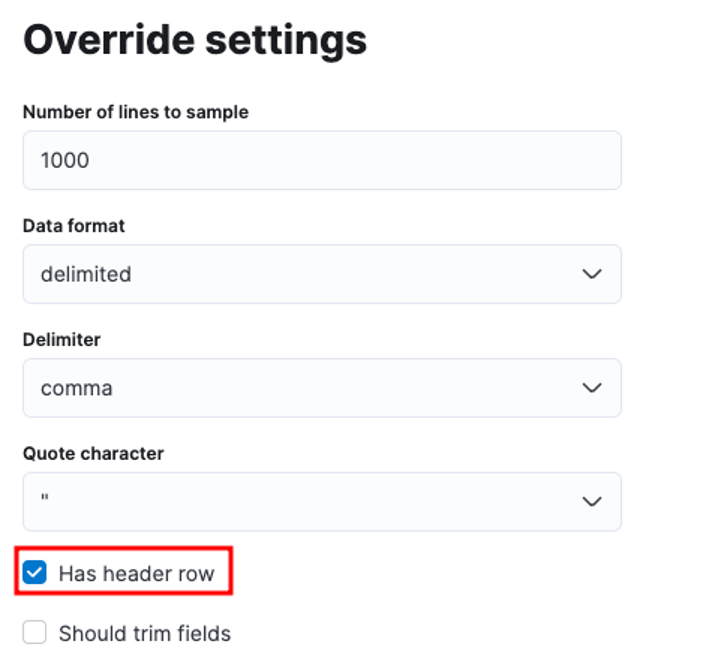
Voimme sitten napsauttaa Käytä ja analysoida tiedot uudelleen. Tämän pitäisi muotoilla tiedot oikeaan muotoon, mukaan lukien kentät.
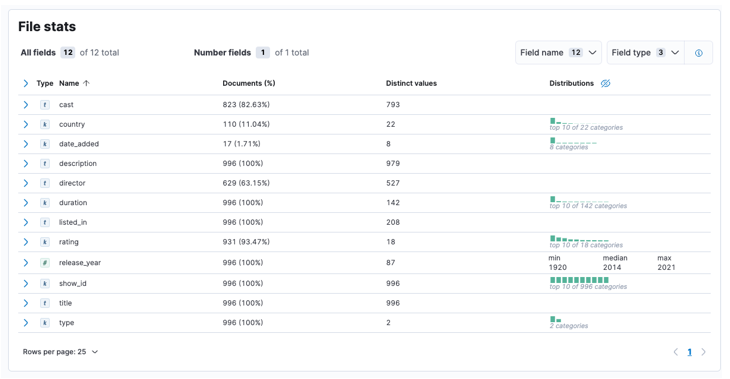
Seuraavaksi voimme napsauttaa tuontia siirtyäksemme tuotuun kojelautaan.
Täällä meidän on luotava hakemisto, johon CSV-tiedot on tallennettu. Voit antaa hakemistollesi minkä tahansa tuetun nimen.
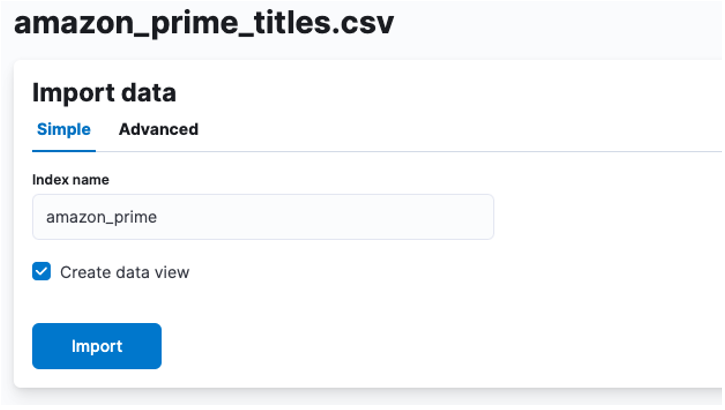
Jos haluat mukauttaa hakemiston ominaisuuksia, kuten sirpaleiden, replikoiden, kartoitusten jne. määrää. Valitse lisäasetus ja säädä asetuksiasi mielesi mukaan.
Napsauta lopuksi tuontia ja katso, kuinka Kibana tekee 'taikansa'. Kun olet valmis, voit käyttää hakemistoasi joko Elasticsearch API:n kautta tai käyttämällä Kibana-hallintapaneelia.
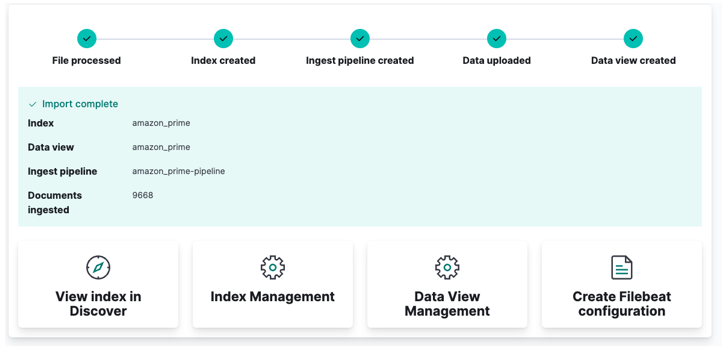
Ja olet valmis!!
Johtopäätös
Tässä viestissä käsittelimme CSV-tietojoukon hakemisen ja tuomisen Elasticsearch-klusteriisi Kibana-hallintapaneelin avulla.
Kiitos lukemisesta ja hyvää koodausta!!